PlagiarismSearch API: Spørgsmål og svar

API (Application Programming Interface) er et sæt rutiner, protokoller og værktøjer til opbygning af softwareapplikationer. Det er skabt for at hjælpe organisationer med at tjekke store mængder tekst gennem deres system. Vores API giver kunderne en unik mulighed for at integrere vores software i deres egne systemer og gøre plagiatkontrollen til en automatiseret proces. Da API-integrationen kræver specifik viden og normalt udføres af tekniske specialister, opstår der mange spørgsmål om dets særlige funktioner for at sikre effektiv drift. I artiklen har vi samlet de mest populære spørgsmål og svar om vores API's ydeevne samt løsninger på de mest almindelige problemer, som vores kunder møder under integrationsprocessen.
Derudover giver API-integrationen vores kunder mulighed for at drage fordel af personlig Storage. Kunder kan uploade deres egne arkiver til Storage-systemet og gemme de tekster, der er tjekket for plagiat via vores API, og derved skabe en individuel Storage. At tjekke tekster for plagiat mod den personlige Storage gør det muligt for vores kunder at opdage og forhindre selvplagiat. Læs mere om funktionaliteterne i den personlige storage i vores guide https://plagiarismsearch.com/plagiarism-database.
Hvilke funktioner er tilgængelige gennem API'en?
- Tjekke tekster og dokumenter for plagiat
- Adgang til plagiatrapporter (historik over plagiatkontroller)
- Mulighed for at uploade kundens database til Storage og se dokumenterne i Storage
- Forhandlere har mulighed for at oprette flere brugerkonti og tildele dem et passende antal indsendelser/ord. Disse muligheder giver hver henvisning mulighed for at bruge sin konto uafhængigt.
Hvordan får jeg adgang til API'en?
Du kan få adgang til vores API gratis i 30 dage. Du vil også få 100 indsendelser og personlig Storage for at teste alle fordelene ved vores service. Registrer dig venligst via dette link for at få adgang til gratis API: https://plagiarismsearch.com/dk/account/signup?from=%2Faccount%2Fapi
Efter registrering, gå til Min Profil - API Indstillinger, og du vil se API-bruger og nøgle, der er givet personligt til din brug. Du skal også bruge vores API-dokumentation (klik på API-dokumentationssektionen https://plagiarismsearch.com/docs/ i din profil for at se den). Giv adgang til ovenstående information til din tekniske specialist for at begynde at bruge vores API.
Hvordan fungerer plagiatkontrol API?
Skemaet for vores API's funktion er som følger:
- Brugeren opretter en rapport (ved at indsende en tekst, uploade en fil eller en offentlig URL) https://plagiarismsearch.com/docs/v3/reports/create
- Hvis din saldo er aktiv – tilføjes dit dokument til kontrol
- Hvis du tjekker 1000-3000 ord på én gang, kan det tage 30-60 sekunder; flere ord tager lidt længere tid
- Efter kontrol af dokumentet får brugeren en `callback_url` POST-anmodning https://plagiarismsearch.com/docs/v3/reports/callback-request
- Eksempel på API-brug i PHP https://plagiarismsearch.com/files/sample-api.zip
Sikrer API'en automatisk tekstverifikation i realtid?
Ja, plagiatkontrolprocessen udføres i realtid. Det tager 1-5 minutter at tjekke en tekst, og tiden afhænger af tekstens størrelse.
Er det muligt at forberede og downloade rapporter gennem API'en?
Ja, du kan downloade PDF- eller HTML-rapport lige efter, at plagiatkontrollen er afsluttet. Alle rapporter gemmes i vores database, så du kan tilgå dem når som helst og downloade https://plagiarismsearch.com/docs/v3/reports/view
Er det muligt at oprette min egen rapportskabelon?
Nej. Vi har 2 tilgængelige rapportskabeloner. Du kan kun indsætte din virksomheds logo i vores rapportskabelon.
Muliggør API'en specifikke dele af tekstverifikationen?
Ja, hvis du taler om at inkludere eller udelukke referencer eller citater, whitelistning af specifikke URLs.
Er det muligt at se historikken for tekstkontrol gennem API'en?
Ja, alle rapporter gemmes i din database.
Er det REST API eller plugin? Er det synkront eller asynkront?
Vi leverer RESTful API. Adgang til vores API-dokumentation findes her: https://plagiarismsearch.com/docs/
Vores API er asynkront. Når plagiatkontrollen er færdig, sender vi en web_hook til brugerens callback_url (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Er der nogen instruktion om, hvordan man implementerer API'en?
Et mere detaljeret skema for API-implementering er som følger:
- Registrer dig på vores hjemmeside her https://plagiarismsearch.com/dk/account/signup
- Sørg for, at din saldo er aktiv, eller tilmeld dig en gratis API-prøveperiode https://plagiarismsearch.com/dk/account/signup?from=%2Faccount%2Fapi
- Gå til Min Profil - API Indstillinger, og du vil se API-bruger og nøgle, der er givet personligt til din brug https://plagiarismsearch.com/account/api
- Send en fil eller tekst til plagiatkontrol ved hjælp af HTTP basic authentication https://plagiarismsearch.com/docs/v3/reports/create.
Her er et eksempel i CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Du vil modtage et svar med rapport-ID:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Vores detektionsmotor starter plagiatkontrolprocessen.
- Efter plagiatkontrollen er afsluttet, sender systemet en POST web_hook til den URL, der er knyttet til det indsendte dokument. Hvis URL ikke er angivet, sender systemet POST web_hook til den URL, der er knyttet til brugerens konto.
- Der er en alternativ måde at sætte status for plagiatkontrollen på, dog ikke anbefalet af vores team. Det er at overvåge rapportstatus https://plagiarismsearch.com/docs/v3/reports/status inden for visse tidsintervaller, og tjekke om rapportstatus er "Finished" (
status=2), "Error" (status=-10) eller "Server error" (status=-11). - Når processen med plagiatkontrol er afsluttet, kan du få detaljerede oplysninger ved hjælp af rapport-ID. Et eksempel findes her: https://plagiarismsearch.com/docs/v3/reports/view
Du kan desuden specificere parameteren `show_relations` for at få flere data.
For eksempel,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // standard
const RELATIONS_TREE = 1;
show_relations = -2 =>returnerer en liste over kilder sorteret efter plagiatprocent. Se`data.sources`responsfeltshow_relations = -1 =>returnerer alle rapportdata. Afsnit, sætninger og kilder med fremhævet tekst. Se`data.paragraphs`responsfeltshow_relations = 1 =>returnerer alle rapportdata. Afsnit, sætninger og kilder med fremhævet tekst. Se`data.paragraphs`responsfelt
Skal scripts vente på resultatet af plagiattesten, eller er der en callback-funktion, der kan kaldes senere for at få dokumentbehandlingsresultatet?
Der er en callback hook POST URL-anmodning, som vi forbinder til brugeren. Du kan også angive din (tilpassede) callback_url i indstillingerne, når du indsender dit dokument (https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Rapporten kan downloades i flere formater: (https://plagiarismsearch.com/docs/v3/reports/view) (Se "Response")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // offentlig pdf-rapport URL
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // offentlig html-rapport URL
"files": [
{
// offentlig EN pdf-rapport URL version 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // offentlig ES pdf-rapport URL version 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // offentlig PL pdf-rapport URL version 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // offentlig EN pdf-rapport URL version 1 (nuværende)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Hvordan får jeg en HTML-rapport?
For at modtage HTML-rapportlink skal du sende GET-anmodning https://plagiarismsearch.com/api/v3/reports/{id} hvor {id} er rapport-ID'en, du vil modtage en rapport for. I “Response” data vil du finde rapportlinket i feltet `data.link`. Også i “Response” vil du finde ‘data.auth_key’, som du kan bruge til at generere 3 mulige varianter af HTML-rapporter.
For eksempel, der er 3 mulige varianter af HTML-rapporter for data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Derudover kan du generere rapportlinks på 4 forskellige sprog (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Du er fri til at kombinere forskellige varianter af HTML-rapporter og sprog for at modtage en nødvendig type rapport på et valgt sprog.
En lignende metode kan bruges til at generere PDF-rapport link (disse URL'er kan ses i “Response” -> `data.files`).
For eksempel:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Jeg kan ikke finde endpoints/detaljer om, hvordan man genererer adgangstokens.
Tokenet vil være i din konto, efter du har registreret dig (https://plagiarismsearch.com/dk/account/api)
Det er nødvendigt at overføre det via Authentication HTTP basic.
Php med CURL
// HTTP basic authentication
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Jeg vil gerne vedhæfte filer i DOCX, PDF og PPT til kontrol. Er det muligt?
Du kan vedhæfte filer i flere formater: (https://plagiarismsearch.com/docs/v3/reports/create) fil-streng eller uploade fil til kontrol.
Derudover kan du sende filer med navn `file`
For eksempel:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Hvordan kan jeg få listen over URL'er, hvor teksten blev fundet?
Du skal bruge show_relations=1 eller hvis du kun har brug for kilder (links => procent af plagiat) eller kalde ruten (POST-metode) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (ikke dokumenteret nu) og bruge feltet `data.sources`
Hvordan kan jeg udelukke min URL fra denne liste?
Du kan kalde ruten (POST-metode) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (ikke dokumenteret nu) efter rapportkontrol med post-parametre
a) POST['url'] = 'https://wikipedia.org' eller
b) POST['source'] = {source.id} (for eksempel data.sources[0].id (integer)) eller
c) array af udeladte URL'er
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array af udeladte kilde-id'er
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Hvis du kalder ruten to gange - vil URL'er blive inkluderet igen, hvilket påvirker den samlede procentdel af plagiat
For mere gennemsigtig brug er det bedre at bruge ruter med de samme parametre som beskrevet ovenfor.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Vi planlægger også at færdiggøre en funktionssæt, der giver mulighed for at udelukke URL her: https://plagiarismsearch.com/api/v3/reports/create
Hvordan kan jeg genberegne plagiatprocenten efter udelukkelse?
Svaret på anmodningen vil inkludere den generelle (ændrede) plagiatprocent data.plagiat
Hvad er "filter_references" & "filter_quotes" godt for?
filter_references=1 => udeluk referencer. Referencetekst har ingen vægt på den samlede plagiatprocent
filter_quotes=1 => udeluk citater i teksten. Citattekst har ingen vægt på den samlede plagiatprocent. Citationsmarkører er
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Er der en måde at implementere API'en via CURL?
Her er retningslinjerne, som kan gøre din CURL-implementering lettere.
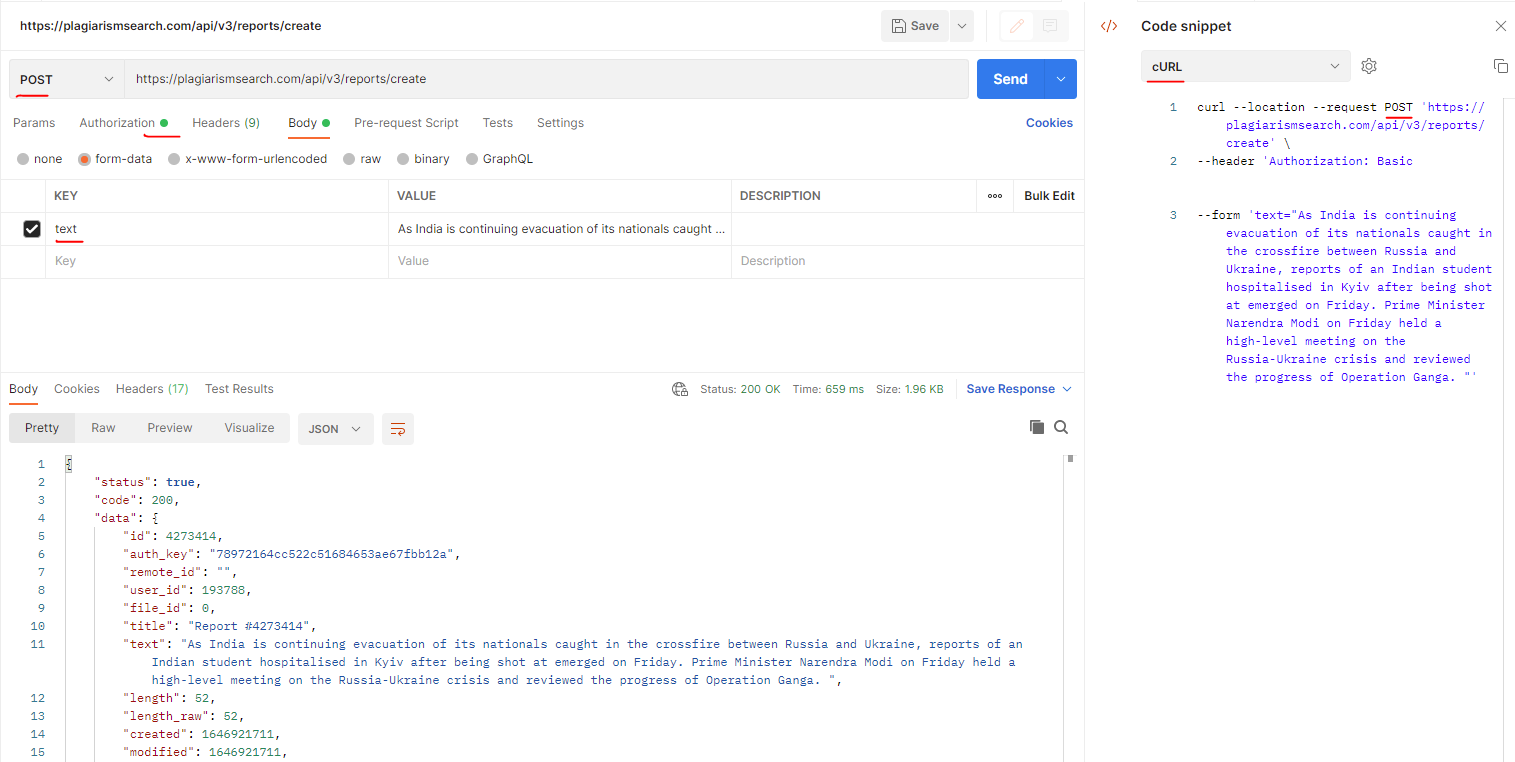
- Upload dokument til plagiatkontrol https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Se rapport https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

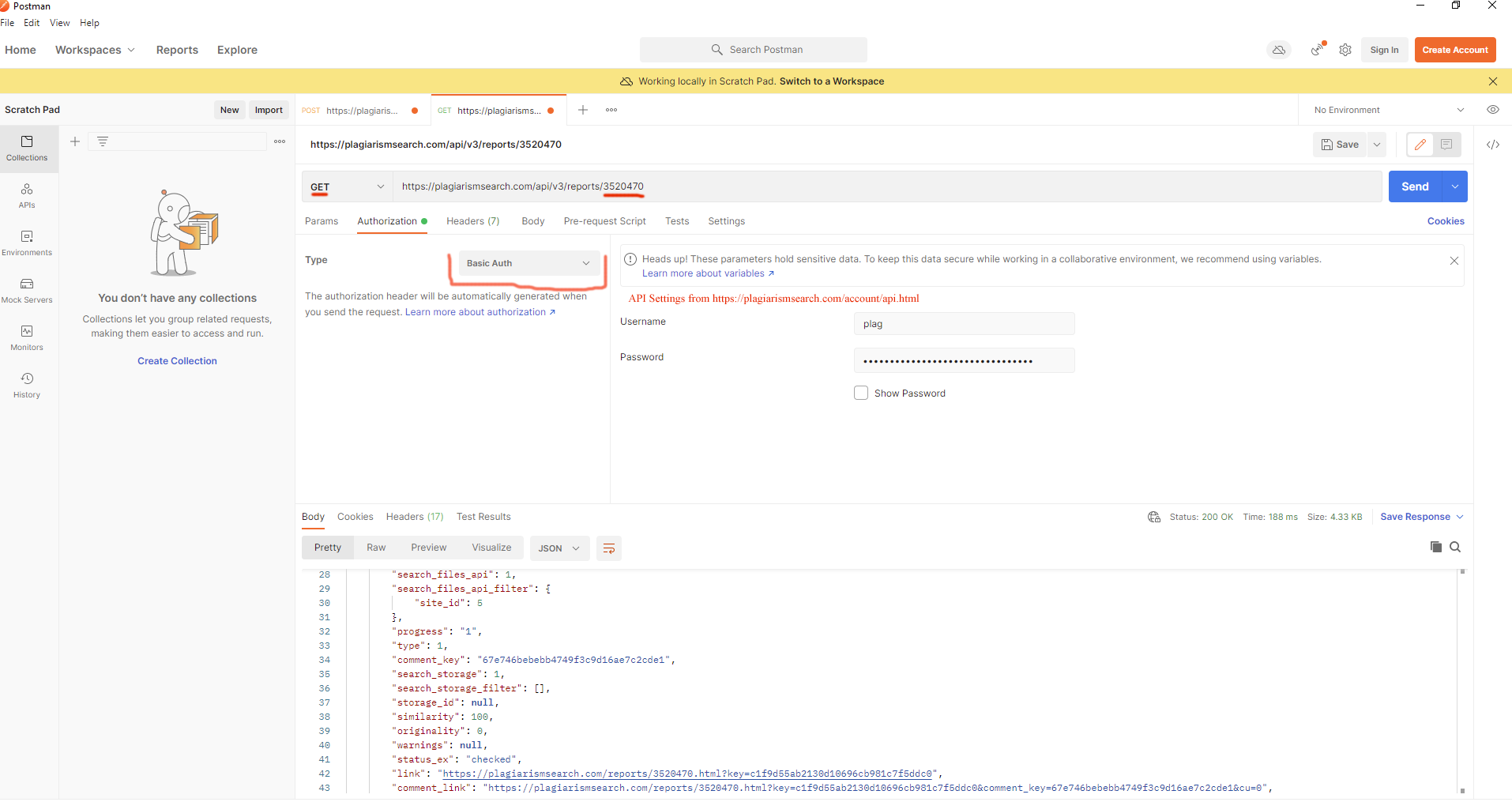
Hvorfor har dokumentet status "Pending" i Storage?
Dokumentet forbliver normalt i Pending-status ikke længe, fra 0 til 6 minutter efter upload eller reupload. Dokumentet tilføjes straks til søgeindekset.
Du kan også tjekke det i programmets kode: hvis 6 minutter er gået, har dokumentet Active-status.
Det er muligt at finde dokumentets status med denne metode:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Se feltet `data.is_in_index`
Hvordan uploader man dokumenter til lageret via API?
Du kan uploade dine dokumenter via API:
POST https://plagiarismsearch.com/api/v3/storage/create
med parametre, som ligner https://plagiarismsearch.com/docs/v3/reports/create
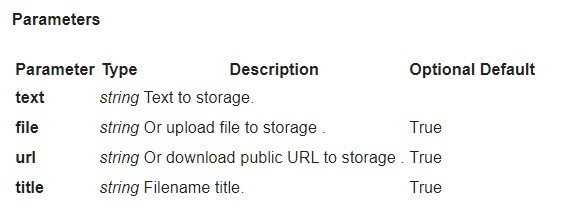
Alternativt kan du uploade dokumenter i en liste eller et arkiv ved hjælp af formularen https://plagiarismsearch.com/storage/upload
Hvad er mulighederne med en forhandlerkonto? Hvordan integrerer jeg det i mit eget system?
Funktionerne, der tilbydes af vores forhandlerkonto, er:
- Hver ny bruger skal oprettes gennem API (du skal bruge login og adgangskode for at oprette hver brugerkonto)
- Du vil have mulighed for at tildele et bestemt antal ord til hver bruger gennem forhandlerkontoen.
Disse muligheder vil give hver klient mulighed for at bruge sin konto uafhængigt, og du vil kunne tilføje ord, der er nødvendige for hver bruger
Teknisk dokumentation nødvendig for integration:
Du skal have en forhandlerkonto
for at kunne oprette kunder. Kontakt os på services@plagiarismsearch.com for
at få adgang til alle mulighederne i en forhandlerkonto.
Opret kunde
For at oprette en ny kunde, send en POST-anmodning https://plagiarismsearch.com/api/v3/reseller-customers/create (Kundens e-mail er et obligatorisk felt)
For eksempel:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
din_bruger_nøgle_kombination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Svar
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}Liste over kunder
Send en GET-anmodning 'https://plagiarismsearch.com/api/v3/reseller-customers' for at modtage listen over alle oprettede kunder.
For eksempel:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic din_bruger_nøgle_kombination=='
Vis saldo
Send en GET-anmodning https://plagiarismsearch.com/api/v3/reseller-customers/balance for at se din saldo.
Se din saldo
Send en GET-anmodning https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} for at se saldoen for en bestemt kunde.
Eksempel på saldo-svar:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Betal til kundens saldo
Tilføj det nødvendige antal indsendelser eller ord til en bestemt kundes konto ved at indtaste bruger-ID og angive beløbet i `words` eller `submissions` feltet (1 submission = 1000 ord).
For eksempel:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic din_bruger_nøgle_kombination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
}Hvordan retter man Fejl: 400 Bad Request, når man indsender tekst til plagiering?
Eksempel på fejl, du kan få, når du indsender tekst til plagiering, kan se sådan ud:
Request Method: PUT
Status Code: 400 Bad Request
Response: Ingen instanser tilgængelige for plagiarismsearch.com
Plagiarism API brugt: https://plagiarismsearch.com/api/v3/reports/create
Løsning:
Kunden bør bruge POST Http-metoden (ikke PUT) som vist på skærmbilledet
Der er en autentificeringsfejl, mens jeg kører /report med GET ved hjælp af request-modulet i Python.
Du skal sende data vedrørende autentificering ved hver ny anmodning.
Vi bruger Basic Authentication, såsom< https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// HTTP basic authentication Php using CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);