PlagiarismSearch API: Domande e Risposte

API (Application Programming Interface) è un insieme di routine, protocolli e strumenti per creare applicazioni software. È stato creato per aiutare le organizzazioni a verificare grandi quantità di testo attraverso il loro sistema. La nostra API offre ai clienti l'opportunità unica di integrare il nostro software nei loro sistemi per rendere il controllo del plagio un processo automatizzato. Poiché l'integrazione API richiede conoscenze specifiche ed è solitamente completata da specialisti tecnici, sorgono molte domande sulle sue caratteristiche particolari per garantire un funzionamento efficiente. In questo articolo abbiamo raccolto le domande-risposte più popolari sulle prestazioni della nostra API e le soluzioni ai problemi più frequenti che i nostri clienti affrontano durante il processo di integrazione.
Inoltre, l'integrazione API offre ai nostri clienti l'opportunità di usufruire di uno Storage personale. I clienti possono caricare i propri archivi nel sistema di Storage e salvare i testi controllati per il plagio tramite la nostra API, creando così uno Storage individuale. Controllare i testi per il plagio rispetto allo Storage personale consente ai nostri clienti di rilevare e prevenire l'auto-plagio. Leggi di più sulle funzionalità dello Storage personale nella nostra guida https://plagiarismsearch.com/it/plagiarism-database.
Quali funzionalità sono disponibili tramite l'API?
- Controllo di testi e documenti per il plagio
- Accesso ai rapporti di plagio (storia dei controlli di plagio)
- Possibilità di caricare il database del cliente nello storage e visualizzare i documenti nello storage
- I rivenditori hanno l'opportunità di creare più account utente e assegnarli con un numero appropriato di invii/parole. Queste opzioni consentiranno a ogni referente di utilizzare il proprio account in modo indipendente.
Come posso ottenere l'accesso all'API?
Puoi avere accesso alla nostra API gratuitamente per 30 giorni. Avrai anche 100 invii e uno Storage personale per testare tutti i vantaggi del nostro servizio. Registrati utilizzando questo link per ricevere l'accesso gratuito all'API: https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
Dopo esserti registrato, vai al tuo Profilo - Impostazioni API, e vedrai API User e Key forniti personalmente per il tuo utilizzo. Inoltre, dovrai utilizzare la nostra documentazione API (clicca sulla sezione documentazione API https://plagiarismsearch.com/docs/ nel tuo profilo per visualizzarla). Fornisci l'accesso alle informazioni sopra riportate al tuo specialista tecnico per iniziare a utilizzare la nostra API.
Come funziona l'API di controllo del plagio?
Lo schema del funzionamento della nostra API è il seguente:
- L'utente crea un rapporto (inviando un testo, caricando un file o un URL pubblico) https://plagiarismsearch.com/docs/v3/reports/create
- Se il tuo saldo è attivo, il tuo documento viene aggiunto per il controllo
- Se controlli 1000-3000 parole contemporaneamente, possono volerci 30-60 secondi; per un numero maggiore di parole, il tempo aumenta leggermente
- Dopo aver controllato il documento, l'utente riceve una richiesta POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- Esempio di utilizzo dell'API in PHP https://plagiarismsearch.com/files/sample-api.zip
L'API garantisce la verifica automatica dei testi in tempo reale?
Sì, il processo di controllo del plagio viene eseguito in tempo reale. Ci vogliono 1-5 minuti per controllare un testo, il tempo di controllo del plagio dipende dalla dimensione del testo.
È possibile preparare e scaricare i rapporti tramite l'API?
Sì, puoi scaricare rapporti in PDF o HTML subito dopo il completamento del controllo del plagio. Tutti i rapporti sono archiviati nel nostro database, quindi puoi accedervi in qualsiasi momento e scaricarli https://plagiarismsearch.com/docs/v3/reports/view.
È possibile creare un proprio modello di rapporto?
No. Abbiamo 2 modelli di rapporto disponibili. Puoi solo inserire il logo della tua azienda nel nostro modello di rapporto.
L'API consente la verifica di parti specifiche del testo?
Sì, se si tratta di includere o escludere riferimenti o citazioni, o di escludere particolari URL.
È possibile visualizzare la cronologia dei controlli dei testi tramite l'API?
Sì, tutti i rapporti sono salvati nel tuo database.
È una REST API o un plugin? È sincrono o asincrono?
Forniamo una RESTful API. L'accesso alla nostra documentazione API è qui: https://plagiarismsearch.com/docs/
La nostra API è asincrona. Quando il controllo del plagio è terminato, inviamo un web_hook all'URL di callback dell'utente (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Ci sono istruzioni su come implementare l'API?
Uno schema più elaborato di implementazione dell'API è il seguente:
- Registrati sul nostro sito web qui https://plagiarismsearch.com/it/account/signup
- Assicurati che il tuo saldo sia attivo o registrati per una prova gratuita dell'API https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
- Vai al tuo Profilo - Impostazioni API, e vedrai API User e Key forniti personalmente per il tuo utilizzo https://plagiarismsearch.com/account/api
- Invia un file o un testo per il controllo del plagio utilizzando l'autenticazione HTTP basic https://plagiarismsearch.com/docs/v3/reports/create. Ecco un esempio in CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Riceverai una risposta con l'ID del rapporto:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Il nostro motore di rilevamento avvia il processo di controllo del plagio.
- Dopo il completamento del controllo del plagio, il sistema invia un POST web_hook all'URL collegato al documento inviato. Nel caso in cui l'URL non sia stato indicato, il sistema invia un POST web_hook all'URL collegato all'account dell'utente.
- C'è un'alternativa per verificare lo stato del controllo del plagio, anche se non raccomandata dal nostro team. Consiste nel monitorare lo stato del rapporto https://plagiarismsearch.com/docs/v3/reports/status a intervalli di tempo definiti, per verificare se lo stato del rapporto è "Completato" (
status=2), "Errore" (status=-10) o "Errore del server" (status=-11). - Quando il processo di controllo del plagio è completato, puoi ottenere informazioni dettagliate utilizzando l'ID del rapporto. Uno degli esempi può essere trovato qui: https://plagiarismsearch.com/docs/v3/reports/view.
Puoi specificare inoltre il parametro `show_relations` per ottenere più dati.
Ad esempio,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // predefinito
const RELATIONS_TREE = 1;
show_relations = -2 =>restituisce un elenco di fonti ordinate per percentuale di plagio. Vedi il campo di risposta`data.sources`show_relations = -1 =>restituisce tutti i dati del report. Paragrafi, frasi e fonti con testo evidenziato. Vedi il campo di risposta`data.paragraphs`show_relations = 1 =>restituisce tutti i dati del report. Paragrafi, frasi e fonti con testo evidenziato. Vedi il campo di risposta`data.paragraphs`
Gli script devono attendere il risultato del test di plagio o esiste una funzione di callback che può essere chiamata in un secondo momento per ottenere il risultato dell'elaborazione del documento?
Esiste un hook di callback con richiesta POST URL che colleghiamo all'utente. Puoi anche indicare il tuo (personalizzato) callback_url nelle impostazioni quando invii il tuo documento (
https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Il report può essere scaricato in diversi formati: (https://plagiarismsearch.com/docs/v3/reports/view) (Vedi "Risposta")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pubblico del report PDF
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pubblico del report HTML
"files": [
{
// URL pubblico del report PDF in EN versione 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // URL pubblico del report PDF in ES versione 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // URL pubblico del report PDF in PL versione 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // URL pubblico del report PDF in EN versione 1 (attuale)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Come posso ottenere un report in HTML?
Per ricevere il link al report in HTML è necessario inviare
una richiesta GET https://plagiarismsearch.com/api/v3/reports/{id}
dove {id} è l'ID del report per il quale si desidera ricevere un report. Nei dati della "Risposta"
troverai il link al report nel campo `data.link`. Inoltre, nella "Risposta"
troverai `data.auth_key` utilizzabile per generare 3 varianti possibili
di report HTML.
Ad esempio, ci sono 3 varianti possibili
di report HTML per data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Inoltre, puoi generare link ai report in 4 lingue diverse (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Sei libero di combinare diverse varianti di report HTML e lingue per ricevere il tipo di report necessario nella lingua scelta.
Schema simile può essere utilizzato per generare il link al report PDF
(questi URL possono essere visualizzati nella "Risposta" -> `data.files`).
Ad esempio:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
Non riesco a trovare i dettagli su come generare i token di accesso.
Il token sarà disponibile nel tuo account dopo la registrazione (https://plagiarismsearch.com/it/account/api)
È necessario trasmetterlo utilizzando l'autenticazione HTTP basic.
Php con CURL
// Autenticazione HTTP basic
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Posso allegare file in formato DOCX, PDF e PPT per il controllo?
Puoi allegare file in diversi formati: (https://plagiarismsearch.com/docs/v3/reports/create) stringa del file oppure caricare il file per il controllo.
Inoltre, puoi inviare file con il nome `file`
Ad esempio:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Come posso ottenere l'elenco degli URL dove è stato trovato il testo?
Devi usare show_relations=1 o, se hai bisogno solo delle fonti (link => percentuale di plagio), chiamare il percorso (metodo POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (non documentato al momento) e usare il campo `data.sources`
Come posso escludere il mio URL da questo elenco?
Puoi chiamare il percorso (metodo POST)
https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (non documentato
al momento) dopo il controllo del report con i parametri POST
a) POST['url'] = 'https://wikipedia.org' oppure
b) POST['source'] = {source.id} (ad esempio data.sources[0].id (integer)) oppure
c) array di URL esclusi
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array di ID delle fonti escluse
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Se chiami il percorso due volte, gli URL saranno inclusi nuovamente, influenzando la percentuale generale di plagio
Per un utilizzo più trasparente, è meglio usare i percorsi con gli stessi parametri descritti sopra.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Abbiamo anche in programma di completare un set di funzionalità che consentirà di escludere URL qui: https://plagiarismsearch.com/api/v3/reports/create
Come posso ricalcolare la percentuale di plagio dopo un'esclusione?
La risposta alla richiesta includerà la percentuale generale (modificata) di plagio data.plagiat
A cosa servono "filter_references" e "filter_quotes"?
filter_references=1 => escludere riferimenti. Il testo dei riferimenti non influisce sulla percentuale totale di plagio
filter_quotes=1 => escludere citazioni nel testo. Il testo delle citazioni non influisce sulla percentuale totale di plagio. I marcatori di citazione sono
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
È possibile implementare l'API tramite CURL?
Ecco le linee guida che potrebbero facilitare l'implementazione di CURL.
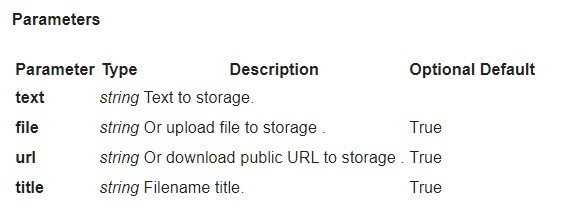
- Caricare un documento per il controllo del plagio https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Visualizzare il report https://plagiarismsearch.com/docs/v3/reports/view
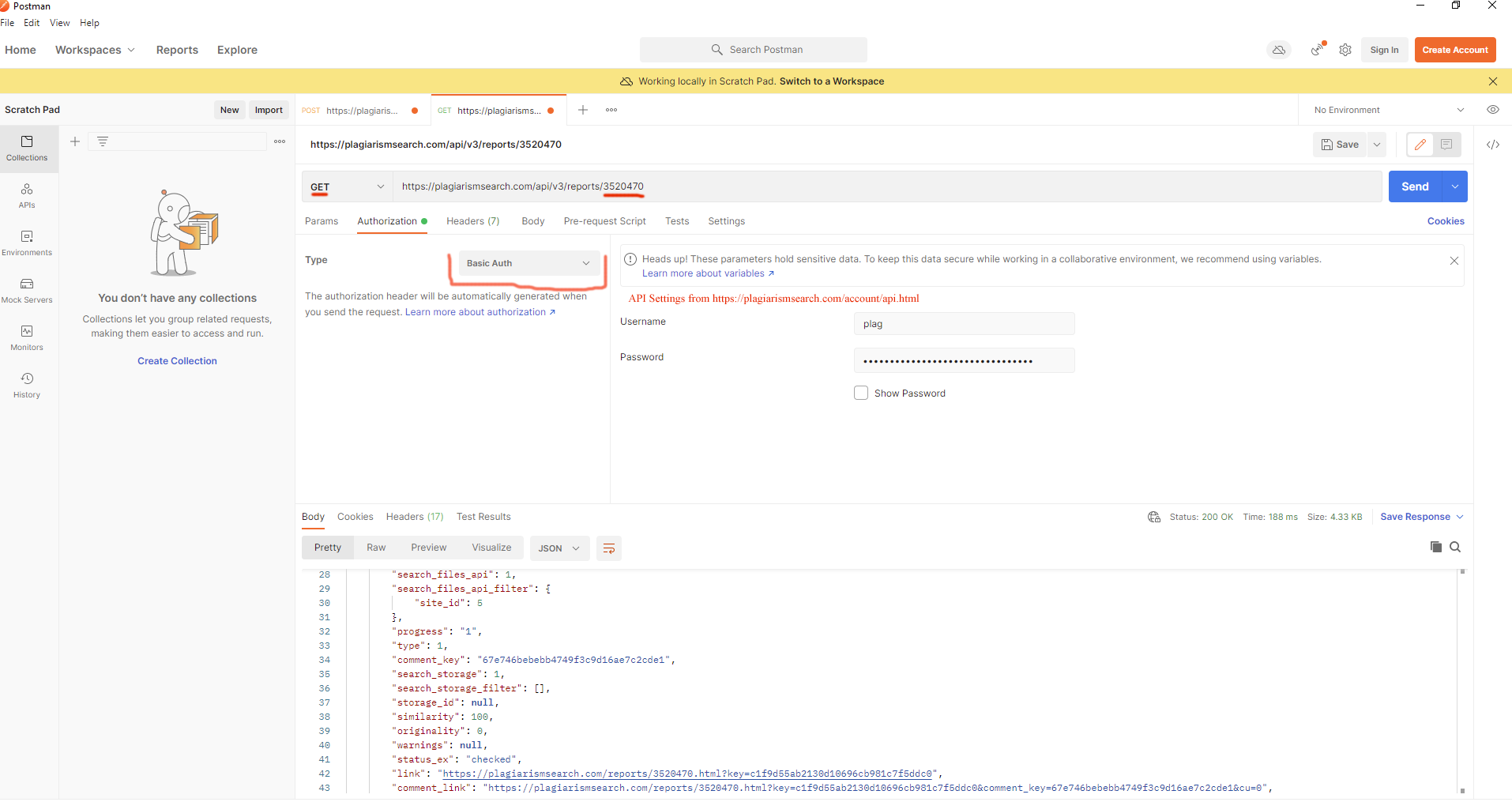
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Perché il documento ha lo stato "Pending" in Storage?
Di solito il documento rimane in stato Pending per poco tempo, da 0 a 6 minuti dopo essere stato caricato o ricaricato. Il documento viene immediatamente aggiunto all'indice di ricerca.
Puoi verificarlo anche nel codice del programma: se sono trascorsi 6 minuti, il documento ha lo stato Active.
È possibile verificare lo stato del documento utilizzando questo metodo:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Vedi il campo `data.is_in_index`
Come caricare documenti nello storage tramite API?
Puoi caricare i tuoi documenti tramite API:
POST https://plagiarismsearch.com/api/v3/storage/create
con parametri simili a https://plagiarismsearch.com/docs/v3/reports/create
In alternativa, puoi caricare documenti in un elenco o un archivio utilizzando il modulo https://plagiarismsearch.com/storage/upload
Quali sono le possibilità di un account rivenditore? Come integrarlo nel mio sistema?
Le funzionalità offerte dal nostro account rivenditore sono:
- Ogni nuovo utente deve essere creato tramite API (avrai bisogno di login e password per creare ogni account utente).
- Avrai l'opportunità di assegnare un numero specifico di parole a ciascun utente tramite l'account rivenditore.
Queste opzioni permetteranno a ciascun cliente di utilizzare il proprio account in modo indipendente, e potrai aggiungere le parole necessarie per ogni utente.
Documentazione tecnica necessaria per l'integrazione:
Devi avere un account di tipo rivenditore per poter creare clienti. Contattaci a services@plagiarismsearch.com per ricevere accesso a tutte le possibilità di un account rivenditore.
Crea cliente
Per creare un nuovo cliente, invia una richiesta POST a https://plagiarismsearch.com/api/v3/reseller-customers/create (L'email del cliente è un campo obbligatorio).
Ad esempio:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Risposta
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}
Elenco clienti
Invia una richiesta GET
'https://plagiarismsearch.com/api/v3/reseller-customers' per ricevere l'elenco di
tutti i clienti creati.
Ad esempio:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Mostra saldi
Invia una richiesta GET https://plagiarismsearch.com/api/v3/reseller-customers/balance
per visualizzare il tuo saldo.
Visualizza il saldo di un cliente
Invia una richiesta GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId}
per visualizzare il saldo di un cliente specifico.
Esempio di risposta sul saldo:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Pagamento sul saldo del cliente
Aggiungi il numero necessario di invii o
parole all'account di un cliente specifico inserendo l'ID utente e la quantità nei
campi `words` o `submissions` (1 submission
= 1000 words).
Ad esempio:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
}
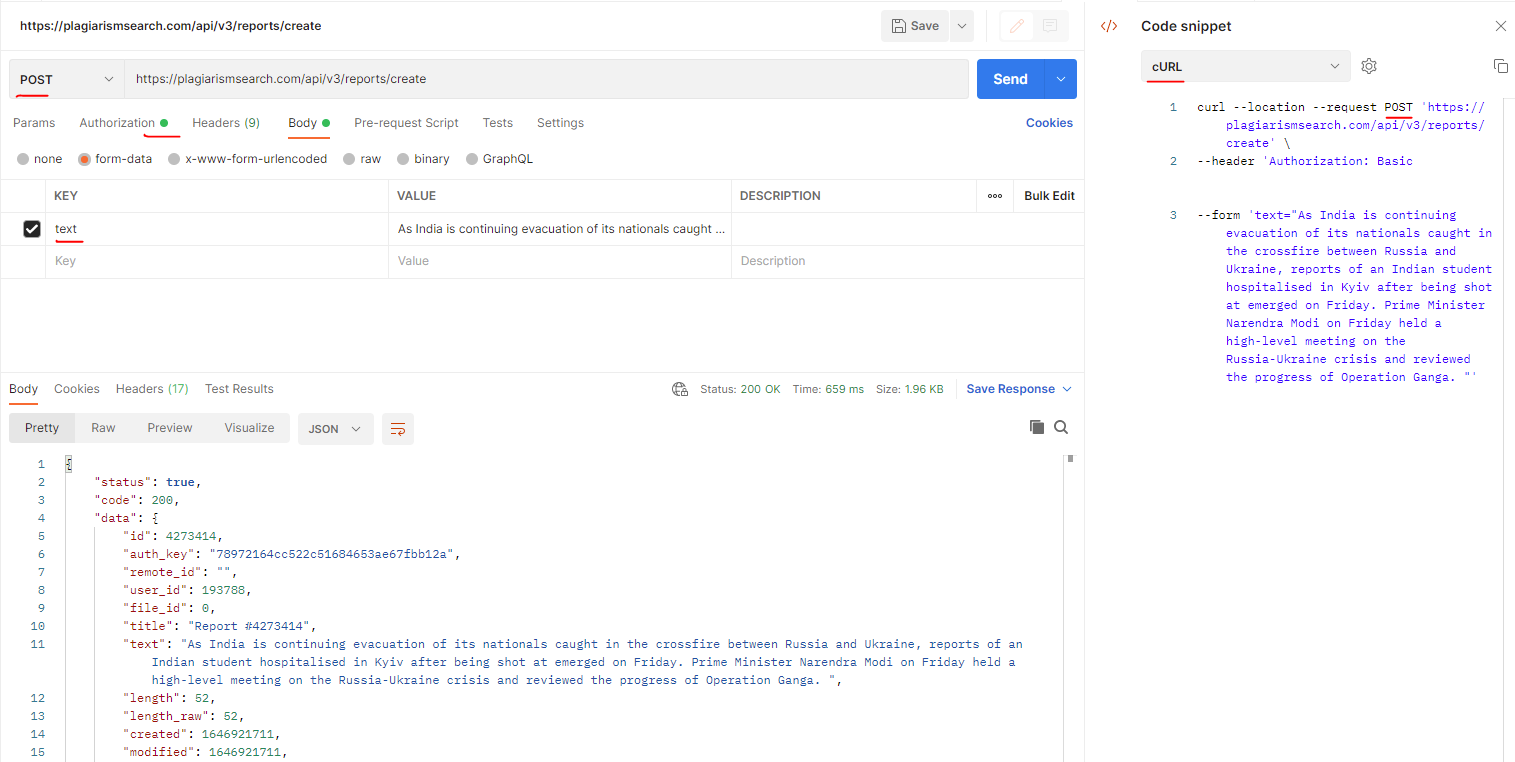
Come correggere l'errore: 400 Bad Request durante l'invio del testo per plagio?
L'errore di esempio che potresti ottenere durante
l'invio del testo per plagio potrebbe essere simile a:
Metodo richiesta: PUT
Codice di stato: 400 Bad Request
Risposta: Nessuna istanza disponibile per
plagiarismsearch.com
API di plagio utilizzata: https://plagiarismsearch.com/api/v3/reports/create
Soluzione:
Il cliente deve utilizzare il metodo POST Http (non
PUT) come nello screenshot
Errore di autenticazione durante l'esecuzione di /report su GET utilizzando il modulo request in Python.
Devi inviare i dati relativi all'autenticazione per ogni nuova richiesta.
Utilizziamo l'Autenticazione di Base, come descritto in https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Autenticazione di base HTTP Php utilizzando CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);