PlagiarismSearch API: Soalan dan Jawapan

API (Application programming interface) adalah sekumpulan rutin, protokol, dan alat untuk membina aplikasi perisian. Ia dicipta untuk membantu organisasi memeriksa sejumlah besar teks melalui sistem mereka. API kami memberikan pelanggan peluang unik untuk mengintegrasikan perisian kami ke dalam sistem mereka sendiri supaya proses semakan plagiat menjadi automatik. Oleh kerana integrasi API memerlukan pengetahuan khusus dan biasanya dilakukan oleh pakar teknikal, banyak soalan timbul mengenai ciri-cirinya untuk memastikan operasi yang efisien. Dalam artikel ini, kami mengumpulkan soalan-jawapan yang paling popular mengenai prestasi API kami, serta penyelesaian bagi masalah yang paling kerap dihadapi pelanggan semasa proses integrasi.
Selain itu, integrasi API memberi pelanggan peluang untuk menggunakan Storage peribadi. Pelanggan boleh memuat naik arkib mereka sendiri ke dalam sistem Storage dan menyimpan teks yang diperiksa untuk plagiat melalui API kami, dengan itu mencipta Storage individu. Menyemak teks terhadap Storage peribadi membolehkan pelanggan mengesan dan mencegah plagiat kendiri. Baca lebih lanjut mengenai fungsi Storage peribadi dalam panduan kami https://plagiarismsearch.com/plagiarism-database.
Ciri-ciri apa yang tersedia melalui API?
- Menyemak teks dan dokumen untuk plagiat
- Akses kepada laporan plagiat (sejarah semakan plagiat)
- Keupayaan untuk memuat naik pangkalan data pelanggan ke dalam Storage dan melihat dokumen dalam Storage
- Penjual semula mempunyai peluang untuk mencipta pelbagai akaun pengguna dan menetapkan bilangan penyerahan/kata yang sesuai. Pilihan ini membolehkan setiap rujukan menggunakan akaunnya secara bebas.
Bagaimana saya boleh mendapat akses kepada API?
Anda boleh mendapat akses ke API kami secara percuma selama 30 hari. Anda juga akan mendapat 100 penyerahan dan Storage peribadi untuk menguji semua manfaat perkhidmatan kami. Sila daftar menggunakan pautan ini untuk menerima akses API percuma: https://plagiarismsearch.com/ms/account/signup?from=%2Faccount%2Fapi
Selepas mendaftar, pergi ke Profil Saya - Tetapan API, dan anda akan melihat API User dan Key yang disediakan secara peribadi untuk kegunaan anda. Selain itu, anda perlu menggunakan dokumentasi API kami (klik pada seksyen dokumentasi API https://plagiarismsearch.com/docs/ dalam Profil Anda untuk melihatnya). Berikan akses kepada maklumat di atas kepada pakar teknikal anda untuk mula menggunakan API kami.
Bagaimana API semakan plagiat berfungsi?
Skema operasi API kami adalah seperti berikut:
- Pengguna mencipta laporan (dengan menghantar teks, memuat naik fail, atau URL awam) https://plagiarismsearch.com/docs/v3/reports/create
- Jika baki anda aktif – dokumen anda ditambah untuk disemak
- Jika anda menyemak 1000-3000 perkataan sekaligus, ia boleh mengambil masa 30-60 saat; lebih banyak perkataan mengambil masa sedikit lebih lama
- Selepas semakan dokumen, pengguna menerima permintaan POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- Contoh penggunaan API dalam PHP https://plagiarismsearch.com/files/sample-api.zip
Adakah API memastikan semakan teks automatik secara masa nyata?
Ya, proses semakan plagiat dijalankan secara masa nyata. Ia mengambil masa 1-5 minit untuk menyemak teks, masa semakan plagiat bergantung pada saiz teks.
Adakah mungkin untuk menyediakan dan memuat turun laporan melalui API?
Ya, anda boleh memuat turun laporan PDF atau HTML sejurus selepas semakan plagiat selesai. Semua laporan disimpan dalam pangkalan data kami, jadi anda boleh mengaksesnya pada bila-bila masa dan memuat turun https://plagiarismsearch.com/docs/v3/reports/view
Adakah mungkin untuk mencipta templat laporan saya sendiri?
Tidak. Kami mempunyai 2 templat laporan yang tersedia. Anda hanya boleh memasukkan logo syarikat anda ke dalam templat laporan kami.
Adakah API membolehkan bahagian tertentu semakan teks?
Ya, jika anda bercakap tentang memasukkan atau mengecualikan rujukan atau sitasi, menyenaraikan URL tertentu.
Adakah mungkin untuk melihat sejarah semakan teks melalui API?
Ya, semua laporan disimpan dalam pangkalan data anda.
Adakah ia REST API atau plugin? Adakah ia segerak atau tak segerak?
Kami menyediakan RESTful API. Akses kepada dokumentasi API kami di sini: https://plagiarismsearch.com/docs/
API kami adalah tak segerak. Apabila semakan plagiat selesai, kami menghantar web_hook ke callback_url pengguna (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Adakah terdapat arahan tentang cara melaksanakan API?
Skema pelaksanaan API yang lebih terperinci adalah seperti berikut:
- Daftar di laman web kami di sini https://plagiarismsearch.com/ms/account/signup
- Pastikan baki anda aktif atau daftar untuk percubaan API percuma https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
- Pergi ke Profil Saya - Tetapan API, dan anda akan melihat API User dan Key yang disediakan secara peribadi untuk kegunaan anda https://plagiarismsearch.com/ms/account/api
- Hantar fail atau teks untuk semakan plagiat menggunakan pengesahan asas HTTP https://plagiarismsearch.com/docs/v3/reports/create.
Berikut adalah contoh dalam CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Anda akan menerima respons dengan ID laporan:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Enjin pengesanan kami memulakan proses semakan plagiat.
- Selepas semakan plagiat selesai, sistem menghantar POST web_hook ke URL yang dikaitkan dengan dokumen yang dihantar. Jika URL tidak ditunjukkan, sistem menghantar POST web_hook ke URL yang dikaitkan dengan akaun pengguna.
- Terdapat cara alternatif untuk menetapkan status semakan plagiat, tetapi tidak disyorkan oleh pasukan kami. Ia adalah untuk memantau status laporan https://plagiarismsearch.com/docs/v3/reports/status
dalam selang masa tertentu, dan menyemak sama ada status laporan adalah
“Selesai” (
status=2), “Ralat” (status=-10), atau “Ralat pelayan” (status=-11) - Apabila proses pemeriksaan plagiarisme selesai, anda boleh mendapatkan maklumat terperinci menggunakan ID laporan. Salah satu contohnya boleh didapati di sini: https://plagiarismsearch.com/docs/v3/reports/view
Anda juga boleh menentukan parameter `show_relations` untuk mendapatkan lebih banyak data.
Contohnya,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // lalai
const RELATIONS_TREE = 1;
show_relations = -2 =>memulangkan senarai sumber yang disusun mengikut peratusan plagiarisme. Lihat medan respons`data.sources`show_relations = -1 =>memulangkan semua data laporan. Perenggan, ayat dan sumber dengan teks yang disorot. Lihat medan respons`data.paragraphs`show_relations = 1 =>memulangkan semua data laporan. Perenggan, ayat dan sumber dengan teks yang disorot. Lihat medan respons`data.paragraphs`
Adakah skrip perlu menunggu hasil ujian plagiarisme atau adakah fungsi panggilan balik yang boleh dipanggil kemudian untuk mendapatkan hasil pemprosesan dokumen?
Terdapat hook panggilan balik POST URL yang kami sambungkan kepada pengguna. Anda juga boleh menentukan callback_url (tersuai) dalam tetapan apabila anda menghantar dokumen anda ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Laporan boleh dimuat turun dalam beberapa format: (https://plagiarismsearch.com/docs/v3/reports/view) (Lihat "Respons")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL laporan PDF awam
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL laporan HTML awam
"files": [
{
// URL laporan PDF EN awam versi 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // URL laporan PDF ES awam versi 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // URL laporan PDF PL awam versi 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // URL laporan PDF EN awam versi 1 (semasa)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Bagaimana saya mendapatkan laporan HTML?
Untuk menerima pautan laporan HTML, anda perlu menghantar
permintaan GET https://plagiarismsearch.com/api/v3/reports/{id}
di mana {id} ialah ID laporan yang anda ingin terima. Dalam "Respons"
data anda akan menemui pautan laporan di medan `data.link`. Juga, dalam "Respons"
anda akan menemui data.auth_key yang membolehkan anda menjana 3 varian
laporan HTML yang berbeza.
Contohnya, terdapat 3 varian laporan HTML untuk data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Selain itu, anda boleh menjana pautan laporan dalam 4 bahasa berbeza (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Anda bebas menggabungkan varian laporan HTML dan bahasa untuk mendapatkan jenis laporan yang diperlukan dalam bahasa pilihan.
Skema yang sama boleh digunakan untuk menjana pautan laporan PDF
(URL ini boleh dilihat dalam "Respons" -> data.files).
Contohnya:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Saya tidak dapat menemui endpoints / butiran tentang cara menjana token akses.
Token akan berada dalam akaun anda selepas anda mendaftar (https://plagiarismsearch.com/account/api)
Token perlu dihantar menggunakan HTTP basic Authentication.
PHP dengan CURL
// HTTP basic authentication
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Saya ingin melampirkan fail DOCX, PDF dan PPT untuk diperiksa. Adakah ia mungkin?
Anda boleh melampirkan fail dalam pelbagai format: (https://plagiarismsearch.com/docs/v3/reports/create) string fail atau muat naik fail untuk pemeriksaan.
Selain itu, anda boleh menghantar fail dengan nama `file`
Contohnya:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Bagaimana saya boleh mendapatkan senarai URL di mana teks ditemui?
Anda mesti menggunakan show_relations=1 atau jika anda hanya memerlukan sumber (pautan => peratus plagiarisme) atau panggil laluan (kaedah POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (tidak didokumentasikan sekarang) dan gunakan medan `data.sources`
Bagaimana saya boleh mengecualikan URL saya daripada senarai ini?
Anda boleh memanggil laluan (kaedah POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (tidak didokumentasikan sekarang) selepas pemeriksaan laporan dengan parameter post
a) POST['url'] = 'https://wikipedia.org' atau
b) POST['source'] = {source.id} (contoh data.sources[0].id (integer)) atau
c) tatasusunan URL yang dilepaskan
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
tatasusunan id sumber yang dilepaskan
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Jika anda memanggil laluan dua kali - URL akan dimasukkan semula, mempengaruhi peratusan plagiarisme secara keseluruhan
Untuk penggunaan yang lebih telus, lebih baik menggunakan laluan dengan parameter yang sama seperti yang diterangkan di atas.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Kami juga merancang untuk melengkapkan set ciri yang membolehkan pengecualian URL di sini: https://plagiarismsearch.com/api/v3/reports/create
Bagaimana saya boleh mengira semula peratusan plagiarisme selepas pengecualian?
Respons kepada permintaan akan termasuk peratusan plagiarisme umum (yang diubah) data.plagiat
Apa kegunaan "filter_references" & "filter_quotes"?
filter_references=1 => mengecualikan rujukan. Teks rujukan tidak mempunyai berat terhadap jumlah peratusan plagiarisme
filter_quotes=1 => mengecualikan petikan dalam teks. Teks petikan tidak mempunyai berat terhadap jumlah peratusan plagiarisme. Penanda petikan adalah
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Adakah cara untuk melaksanakan API melalui CURL?
Berikut adalah garis panduan, yang boleh memudahkan pelaksanaan CURL anda.
- Muat naik dokumen untuk pemeriksaan plagiarisme https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Lihat laporan https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Mengapa dokumen mempunyai status "Pending" dalam Storage?
Dokumen biasanya berada dalam status Pending tidak lama, dari 0 hingga 6 minit selepas ia dimuat naik atau dimuat naik semula. Dokumen ditambah segera ke indeks Pencarian.
Anda juga boleh menyemaknya dalam kod program: jika 6 minit telah berlalu, dokumen mempunyai status Aktif.
Adalah mungkin untuk mengetahui status dokumen menggunakan kaedah berikut:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Lihat medan `data.is_in_index`
Bagaimana cara memuat naik dokumen ke storan melalui API?
Anda boleh memuat naik dokumen anda melalui API:
POST https://plagiarismsearch.com/api/v3/storage/create
dengan parameter, yang serupa dengan https://plagiarismsearch.com/docs/v3/reports/create
Sebagai alternatif, anda boleh memuat naik dokumen dalam senarai atau arkib menggunakan borang https://plagiarismsearch.com/storage/upload
Apakah kemungkinan akaun penjual semula? Bagaimana saya mengintegrasikannya dalam sistem saya sendiri?
Fungsi yang ditawarkan oleh akaun penjual semula kami ialah:
- Setiap pengguna baru mesti dibuat melalui API (anda memerlukan login dan kata laluan untuk membuat setiap akaun pengguna)
- Anda akan mempunyai peluang untuk memberikan bilangan perkataan tertentu untuk setiap pengguna melalui akaun penjual semula.
Pilihan ini akan membolehkan setiap pelanggan menggunakan akaun mereka secara bebas, dan anda akan dapat menambah perkataan yang diperlukan untuk setiap pengguna
Dokumentasi teknikal yang diperlukan untuk integrasi:
Anda perlu mempunyai akaun jenis penjual semula
untuk dapat membuat pelanggan. Hubungi kami di services@plagiarismsearch.com untuk
menerima akses kepada semua kemungkinan akaun penjual semula.
Buat pelanggan
Untuk membuat pelanggan baru, hantar permintaan POST https://plagiarismsearch.com/api/v3/reseller-customers/create (Email pelanggan adalah medan wajib)
Contoh:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
kombinasi_kunci_pengguna_anda===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Respons
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}Senarai pelanggan
Hantar permintaan GET 'https://plagiarismsearch.com/api/v3/reseller-customers' untuk menerima senarai semua pelanggan yang telah dibuat.
Contoh:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic kombinasi_kunci_pengguna_anda=='
Tunjukkan baki
Hantar permintaan GET https://plagiarismsearch.com/api/v3/reseller-customers/balance untuk melihat baki anda.
Dapatkan baki anda
Hantar permintaan GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} untuk melihat baki pelanggan tertentu.
Contoh respons baki:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Bayar ke baki pelanggan
Tambah bilangan penghantaran atau perkataan yang diperlukan ke akaun pelanggan tertentu dengan memasukkan ID pengguna dan memasukkan jumlah ke medan `words` atau `submissions` (1 penghantaran = 1000 perkataan).
Contoh:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic kombinasi_kunci_pengguna_anda==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
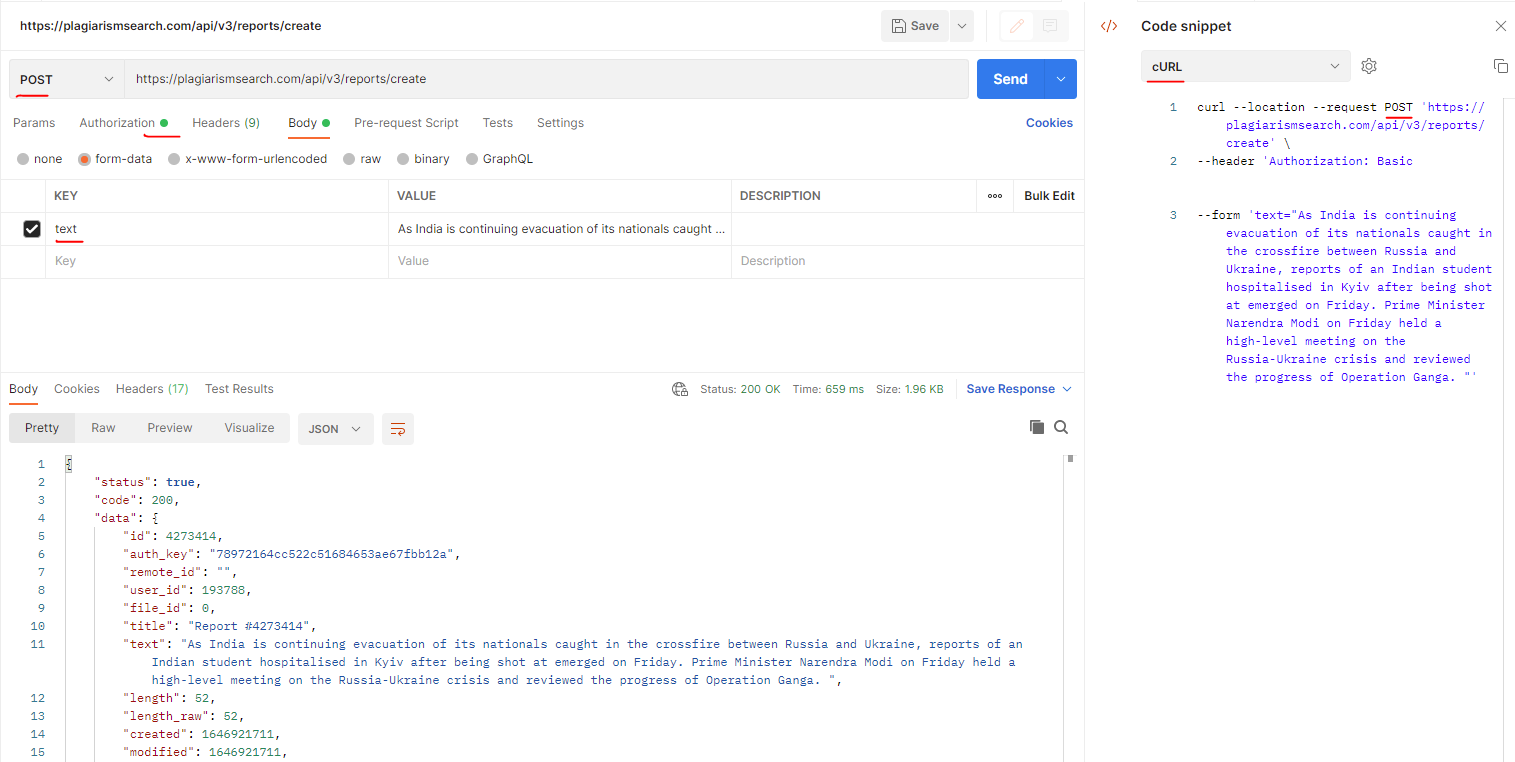
}Bagaimana membetulkan Ralat: 400 Bad Request apabila menghantar teks untuk plagiarism?
Contoh ralat yang mungkin anda terima apabila menghantar teks untuk plagiarism mungkin kelihatan seperti:
Kaedah Permintaan: PUT
Status Kod: 400 Bad Request
Respons: Tiada contoh tersedia untuk plagiarismsearch.com
API Plagiarism yang digunakan: https://plagiarismsearch.com/api/v3/reports/create
Penyelesaian:
Pelanggan harus menggunakan kaedah POST Http (bukan PUT) seperti dalam tangkapan skrin
Terdapat ralat pengesahan semasa saya menjalankan /report pada GET menggunakan modul request dalam Python.
Anda perlu menghantar data berkaitan pengesahan pada setiap permintaan baru.
Kami menggunakan Basic Authentication, seperti< https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Pengesahan asas HTTP Php menggunakan CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);