API PlagiarismSearch: Perguntas e Respostas

A API (Interface de Programação de Aplicações) é um conjunto de rotinas, protocolos e ferramentas para a construção de aplicações de software. Ela é criada para ajudar as organizações a verificar grandes quantidades de texto por meio de seu sistema. Nossa API oferece aos clientes uma oportunidade única de integrar nosso software aos seus próprios sistemas, tornando o processo de verificação de plágio automatizado. Como a integração da API requer conhecimento específico e normalmente é realizada por especialistas técnicos, surgem muitas perguntas sobre suas características particulares para garantir uma operação eficiente. Neste artigo, reunimos as perguntas e respostas mais populares sobre o desempenho da nossa API, bem como soluções para os problemas mais frequentes que nossos clientes enfrentam durante o processo de integração.
Além disso, a integração da API oferece aos nossos clientes a oportunidade de aproveitar o Armazenamento pessoal. Os clientes podem fazer o upload de seus próprios arquivos no sistema de Armazenamento e salvar os textos verificados quanto ao plágio por meio de nossa API, criando assim um Armazenamento individual. Verificar textos para plágio contra o Armazenamento pessoal permite que nossos clientes detectem e previnam o autoplagiado. Leia mais sobre as funcionalidades do armazenamento pessoal em nosso guia https://plagiarismsearch.com/plagiarism-database.
Quais recursos estão disponíveis através da API?
- Verificação de textos e documentos quanto a plágio
- Acesso aos relatórios de plágio (histórico de verificações de plágio)
- Capacidade de carregar o banco de dados do cliente no armazenamento e visualizar os documentos no armazenamento
- Revendedores têm a oportunidade de criar várias contas de usuário e atribuir a elas o número apropriado de envios/palavras. Essas opções permitirão que cada referenciado use sua conta de forma independente.
Como posso obter acesso à API?
Você pode acessar nossa API gratuitamente por 30 dias. Você também terá 100 envios e Armazenamento pessoal para testar todos os benefícios de nosso serviço. Por favor, registre-se usando este link para receber acesso gratuito à API: https://plagiarismsearch.com/pt/account/signup?from=%2Faccount%2Fapi
Após o registro, vá para Meu Perfil - Configurações da API, e você verá o Usuário e a Chave da API fornecidos pessoalmente para o seu uso. Além disso, você precisará usar nossa documentação da API (clique na seção de documentação da API https://plagiarismsearch.com/docs/ no seu Perfil para visualizá-la). Forneça acesso às informações acima para o seu especialista técnico começar a usar nossa API.
Como funciona a API de verificação de plágio?
A esquema de operação da nossa API é o seguinte:
- O usuário cria um relatório (enviando um texto, fazendo upload de um arquivo ou uma URL pública) https://plagiarismsearch.com/docs/v3/reports/create
- Se o seu saldo estiver ativo – seu documento será adicionado para verificação
- Se você verificar 1000-3000 palavras de uma vez, pode levar de 30 a 60 segundos; mais palavras levam um pouco mais de tempo
- Após verificar o documento, o usuário recebe uma solicitação POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- O exemplo de uso da API em PHP https://plagiarismsearch.com/files/sample-api.zip
A API garante a verificação automática do texto em tempo real?
Sim, o processo de verificação de plágio é realizado em tempo real. Leva de 1 a 5 minutos para verificar um texto, o tempo de verificação de plágio depende do tamanho do texto.
É possível preparar e baixar relatórios através da API?
Sim, você pode baixar o relatório em PDF ou HTML logo após a verificação de plágio ser concluída. Todos os relatórios são armazenados em nosso banco de dados, portanto, você pode acessá-los a qualquer momento e baixá-los https://plagiarismsearch.com/docs/v3/reports/view
É possível criar meu próprio modelo de relatório?
Não. Temos 2 modelos de relatórios disponíveis. Você pode apenas inserir o logotipo da sua empresa no nosso modelo de relatório.
A API permite a verificação de partes específicas do texto?
Sim, se você está falando sobre incluir ou excluir referências ou citações, colocando URLs específicas na lista branca.
É possível visualizar o histórico de verificações de texto através da API?
Sim, todos os relatórios são salvos no seu banco de dados.
É uma API REST ou plugin? É síncrona ou assíncrona?
Oferecemos uma API RESTful. O acesso à nossa documentação da API está aqui: https://plagiarismsearch.com/docs/
Nosso API é assíncrono. Quando a verificação de plágio é concluída, enviamos um web_hook para o `callback_url` do usuário (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Existe alguma instrução sobre como implementar a API?
Um esquema mais detalhado de implementação da API é o seguinte:
- Registre-se em nosso site aqui https://plagiarismsearch.com/pt/account/signup
- Certifique-se de que seu saldo está ativo ou inscreva-se para um teste gratuito da API https://plagiarismsearch.com/pt/account/signup?from=%2Faccount%2Fapi
- Vá para Meu Perfil - Configurações da API, e você verá o Usuário da API e a Chave fornecidos pessoalmente para o seu uso https://plagiarismsearch.com/pt/account/api
- Envie um arquivo ou texto para
verificação de plágio usando autenticação básica HTTP https://plagiarismsearch.com/docs/v3/reports/create.
Aqui está um exemplo em CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Você receberá uma resposta
com o ID do relatório:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Nosso motor de detecção inicia o processo de verificação de plágio.
- Após a verificação de plágio ser concluída, o sistema envia um POST web_hook para a URL vinculada ao documento submetido. Caso a URL não tenha sido indicada, o sistema envia um POST web_hook para a URL vinculada à conta do usuário.
- Existe uma maneira alternativa de definir
o status da verificação de plágio, embora não seja recomendada por nossa equipe. Consiste em monitorar
o status do relatório https://plagiarismsearch.com/docs/v3/reports/status
dentro de certos intervalos de tempo, e verificar se o status do relatório é
“Concluído” (
status=2), “Erro” (status=-10), ou “Erro no servidor” (status=-11) - Quando o processo de verificação de plágio for concluído, você poderá obter informações detalhadas usando o ID do relatório. Um dos exemplos pode ser encontrado aqui: https://plagiarismsearch.com/docs/v3/reports/view
Você pode também especificar o parâmetro `show_relations` para obter mais dados.
Por exemplo,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // padrão
const RELATIONS_TREE = 1;
show_relations = -2 =>retorna lista de fontes ordenadas por porcentagem de plágio. Veja o campo de resposta`data.sources`show_relations = -1 =>retorna todos os dados do relatório. Parágrafos, frases e fontes com texto destacado. Veja o campo de resposta`data.paragraphs`show_relations = 1 =>retorna todos os dados do relatório. Parágrafos, frases e fontes com texto destacado. Veja o campo de resposta`data.paragraphs`
Os scripts precisam esperar pelo resultado do teste de plágio ou há uma função de callback que pode ser chamada em um momento posterior para obter o resultado do processamento do documento?
Há uma solicitação POST do URL do hook de callback que conectamos ao usuário. Você também pode indicar seu (personalizado) callback_url nas configurações ao enviar seu documento ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
O relatório pode ser baixado em vários formatos: (https://plagiarismsearch.com/docs/v3/reports/view) (Veja "Resposta")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pública do relatório em PDF
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pública do relatório em HTML
"files": [
{
// URL pública do relatório em PDF versão 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // URL pública do relatório em PDF versão 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // URL pública do relatório em PDF versão 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // URL pública do relatório em PDF versão 1 (atual)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Como eu obtenho um relatório em HTML?
Para receber o link do relatório em HTML, você precisa enviar uma solicitação GET https://plagiarismsearch.com/api/v3/reports/{id} onde {id} é o ID do relatório para o qual você deseja receber um relatório. Na resposta, você encontrará o link do relatório no campo `data.link`. Também, na resposta, você encontrará o 'data.auth_key' usando o qual você pode gerar 3 variantes possíveis de relatórios HTML.
Por exemplo, há 3 variantes possíveis de relatórios HTML para data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Adicionalmente, você pode gerar links de relatório em 4 idiomas diferentes (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Você pode combinar diferentes variantes dos relatórios HTML e idiomas para receber o tipo de relatório necessário no idioma escolhido.
Um esquema semelhante pode ser usado para gerar o link do relatório em PDF (esses URLs podem ser visualizados em “Resposta” -> `data.files`).
Por exemplo:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Não consigo encontrar pontos finais/detalhes sobre como gerar tokens de acesso.
O token estará na sua conta depois que você se registrar (https://plagiarismsearch.com/pt/account/api)
É necessário transmiti-lo usando a autenticação HTTP básica.
Php com CURL
// Autenticação HTTP básica
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Gostaria de anexar os arquivos em DOCX, PDF e PPT para verificar. Isso é possível?
Você pode anexar arquivos em vários formatos: (https://plagiarismsearch.com/docs/v3/reports/create) string do arquivo Ou carregar o arquivo para verificação.
Além disso, você pode enviar arquivos com o nome `file`
Por exemplo:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Como posso obter a lista de URLs onde o texto foi encontrado?
Você deve usar show_relations=1 ou se precisar apenas das fontes (links => percentual de plágio) ou chamar a rota (método POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (não documentado agora) e usar o campo `data.sources`
Como posso excluir meu URL dessa lista?
Você pode chamar a rota (método POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (não documentado agora) após a verificação do relatório com parâmetros POST
a) POST['url'] = 'https://wikipedia.org' ou
b) POST['source'] = {source.id} (por exemplo, data.sources[0].id (inteiro)) ou
c) array de URLs excluídos
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array de IDs de fontes excluídas
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Se você chamar a rota duas vezes - os URLs serão incluídos novamente, influenciando o percentual geral de plágio
Para um uso mais transparente, é melhor usar rotas com os mesmos parâmetros descritos acima.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Também planejamos completar um conjunto de recursos que permitiria excluir URLs aqui: https://plagiarismsearch.com/api/v3/reports/create
Como posso recalcular a porcentagem de plágio após a exclusão?
A resposta à solicitação incluirá a porcentagem geral (alterada) de plágio data.plagiat
Para que servem "filter_references" e "filter_quotes"?
filter_references=1 => exclui referências. O texto de referências não tem peso na porcentagem total de plágio
filter_quotes=1 => exclui citações no texto. O texto das citações não tem peso na porcentagem total de plágio. Os marcadores de citação são
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Há uma maneira de implementar a API via CURL?
Aqui estão as diretrizes, que podem facilitar sua implementação com CURL.
- Carregar documento para verificação de plágio https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic sua_combinação_usuario_chave==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Visualizar relatório https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic sua_combinação_usuario_chave=='

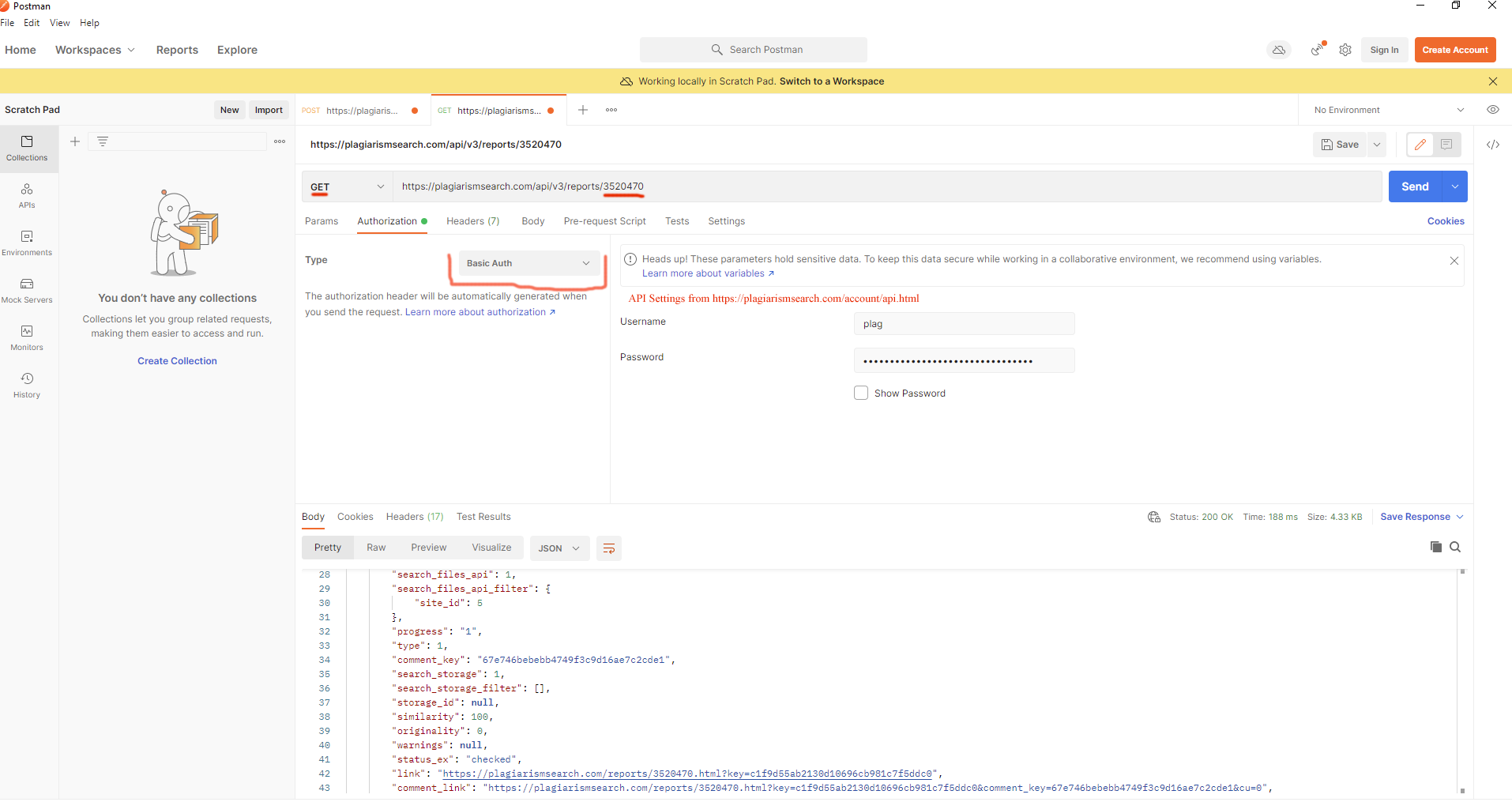
Por que o documento tem o status “Pendentes” no Armazenamento?
O documento geralmente fica no status Pendentes por um curto período, de 0 a 6 minutos depois de ser carregado ou re-enviado. O documento é imediatamente adicionado ao índice de Pesquisa.
Você também pode verificar no código do programa: se passaram 6 minutos, o documento terá o status Ativo.
É possível descobrir o status do documento usando este método:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Veja o campo `data.is_in_index`
Como carregar documentos para o armazenamento via API?
Você pode carregar seus documentos via API:
POST https://plagiarismsearch.com/api/v3/storage/create
com parâmetros, semelhantes aos de https://plagiarismsearch.com/docs/v3/reports/create
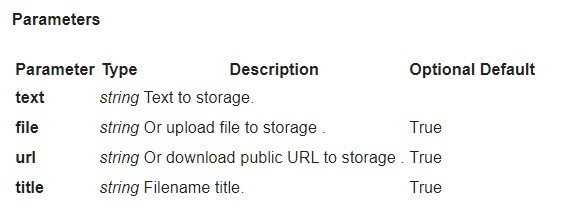
Alternativamente, você pode carregar documentos em uma lista ou arquivo usando o formulário https://plagiarismsearch.com/storage/upload
Quais são as possibilidades de uma conta de revendedor? Como integrá-la ao meu próprio sistema?
As funcionalidades oferecidas pela nossa conta de revendedor são:
- Cada novo usuário deve ser criado através da API (você precisará de login e senha para criar cada conta de usuário)
- Você terá a oportunidade de distribuir um número particular de palavras para cada usuário através da conta de revendedor.
Essas opções darão a possibilidade para cada cliente usar sua conta de forma independente, e você poderá adicionar as palavras necessárias para cada usuário
Documentação técnica necessária para integração:
Você precisa ter uma conta de revendedor
para poder criar clientes. Entre em contato conosco pelo email services@plagiarismsearch.com para
receber acesso às possibilidades completas de uma conta de revendedor.
Criar cliente
Para criar um novo cliente, envie uma solicitação POST https://plagiarismsearch.com/api/v3/reseller-customers/create (O email do cliente é um campo obrigatório)
Por exemplo:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="Nome do Usuário"' \
--form 'password="123456"'
Resposta
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"Nome do Usuário",
"status":"ativo",
"password":"123456"
},
"version":"3.0.0"
}Lista de clientes
Envie uma solicitação GET 'https://plagiarismsearch.com/api/v3/reseller-customers' para receber a lista de todos os clientes que foram criados.
Por exemplo:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Mostrar saldos
Envie uma solicitação GET https://plagiarismsearch.com/api/v3/reseller-customers/balance para visualizar seu saldo.
Obter seu saldo
Envie uma solicitação GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} para visualizar o saldo de um cliente específico.
Exemplo de resposta de saldo:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Pagar para o saldo do cliente
Adicione o número necessário de envios ou palavras à conta de um cliente específico, inserindo o ID do usuário e colocando o valor no campo `words` ou `submissions` (1 submission = 1000 palavras).
Por exemplo:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
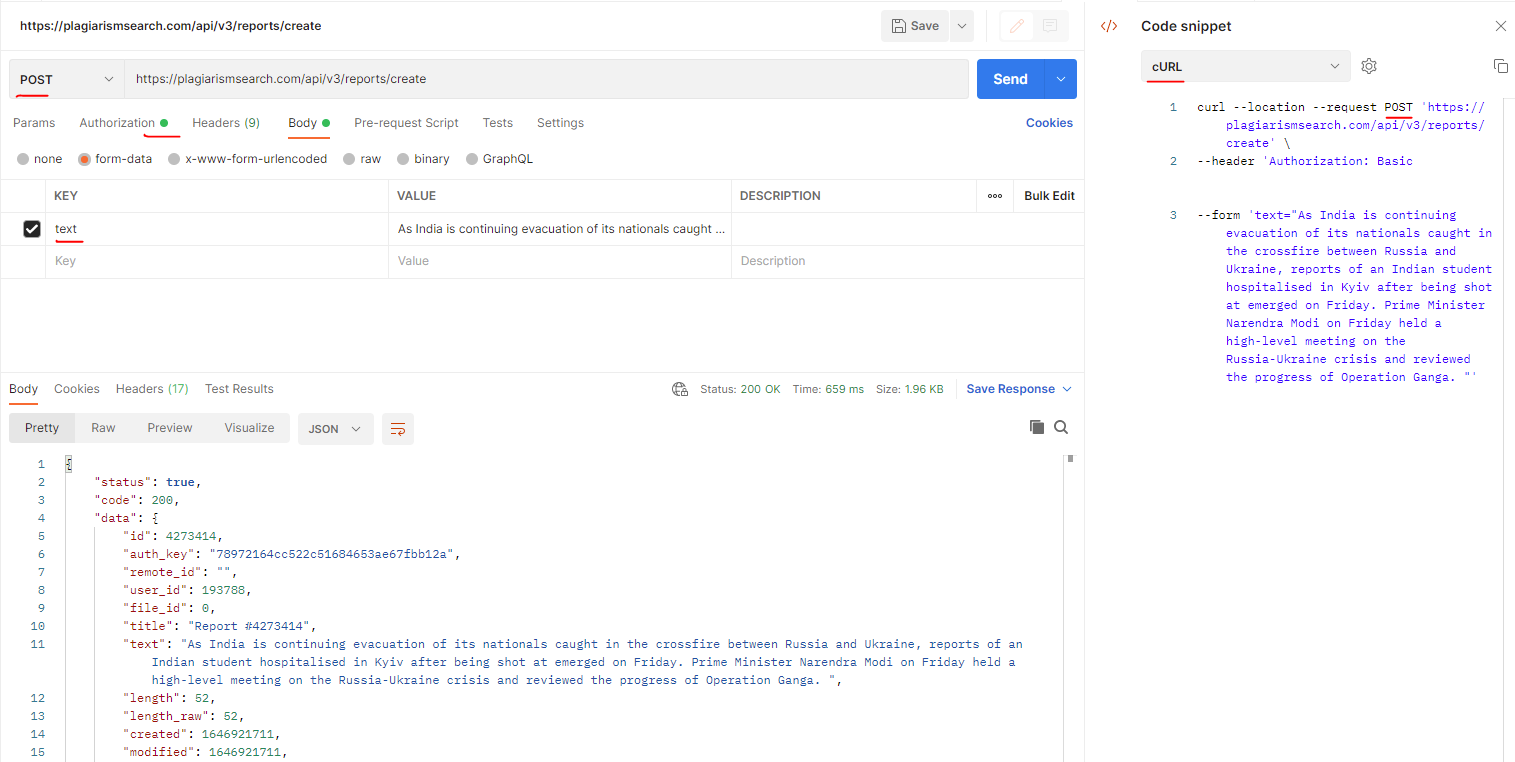
}Como corrigir o erro: 400 Bad Request ao enviar texto para verificação de plágio?
O exemplo de erro que você pode obter ao enviar texto para verificação de plágio pode ser parecido com:
Método de solicitação: PUT
Código de Status: 400 Bad Request
Resposta: Nenhuma instância disponível para plagiarismsearch.com
API de Plágio usada: https://plagiarismsearch.com/api/v3/reports/create
Solução:
O cliente deve usar o método POST (não PUT) como mostrado na captura de tela
Há um erro de autenticação enquanto estou executando o /report no GET usando o módulo request no Python.
Você deve enviar os dados de autenticação em cada nova solicitação.
Utilizamos autenticação básica, como https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Autenticação básica HTTP Php usando CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);