PlagiarismSearch API: Vragen en Antwoorden

API (Application Programming Interface) is een set routines, protocollen en tools voor het bouwen van softwareapplicaties. Het is ontworpen om organisaties te helpen grote hoeveelheden tekst via hun systeem te controleren. Onze API biedt klanten een unieke kans om onze software in hun eigen systemen te integreren om plagiaatcontrole tot een geautomatiseerd proces te maken. Aangezien API-integratie specifieke kennis vereist en meestal door technische specialisten wordt uitgevoerd, ontstaan er veel vragen over de specifieke functies om een efficiënte werking te garanderen. In dit artikel hebben we de meest populaire vragen en antwoorden over onze API-prestaties verzameld en oplossingen voor de meest voorkomende problemen waarmee onze klanten te maken krijgen tijdens het integratieproces.
Bovendien biedt de API-integratie onze klanten de mogelijkheid om gebruik te maken van persoonlijke opslag. Klanten kunnen hun eigen archieven uploaden in het opslagsysteem en de via onze API gecontroleerde teksten opslaan, waardoor een individuele opslag wordt gecreëerd. Het controleren van teksten op plagiaat in de persoonlijke opslag stelt onze klanten in staat om zelfplagiaat op te sporen en te voorkomen. Lees meer over de functionaliteiten van de persoonlijke opslag in onze gids https://plagiarismsearch.com/plagiarism-database.
Welke functies zijn beschikbaar via de API?
- Controleren van teksten en documenten op plagiaat
- Toegang tot plagiaatrapporten (geschiedenis van plagiaatcontroles)
- Mogelijkheid om de database van de klant naar de opslag te uploaden en documenten in de opslag te bekijken
- Resellers hebben de mogelijkheid om meerdere gebruikersaccounts aan te maken en deze toe te wijzen met het juiste aantal inzendingen/woorden. Deze opties geven elke referral de mogelijkheid om zijn/haar account onafhankelijk te gebruiken.
Hoe krijg ik toegang tot de API?
U kunt 30 dagen gratis toegang krijgen tot onze API. U krijgt ook 100 inzendingen en persoonlijke opslag om alle voordelen van onze service te testen. Registreer u via deze link om toegang te krijgen tot de gratis API: https://plagiarismsearch.com/nl/account/signup?from=%2Faccount%2Fapi
Na registratie gaat u naar Mijn Profiel - API-instellingen, waar u API-gebruiker en sleutel persoonlijk voor uw gebruik ziet. U moet ook onze API-documentatie gebruiken (klik in uw profiel op de sectie API-documentatie https://plagiarismsearch.com/docs/ om het te bekijken). Geef bovenstaande informatie door aan uw technische specialist om te beginnen met het gebruik van onze API.
Hoe werkt de plagiaatcontrole-API?
Het schema van onze API-werking is als volgt:
- De gebruiker maakt een rapport aan (door een tekst in te dienen, een bestand te uploaden of een openbare URL) https://plagiarismsearch.com/docs/v3/reports/create
- Als uw saldo actief is – wordt uw document toegevoegd voor controle
- Als u 1000-3000 woorden tegelijk controleert, kan het 30-60 seconden duren; meer woorden duren iets langer
- Na de controle van het document krijgt de gebruiker een `callback_url` POST-verzoek https://plagiarismsearch.com/docs/v3/reports/callback-request
- Voorbeeld van API-gebruik in PHP https://plagiarismsearch.com/files/sample-api.zip
Voert de API automatische tekstverificatie in realtime uit?
Ja, het plagiaatcontroleproces wordt in realtime uitgevoerd. Het duurt 1-5 minuten om een tekst te controleren, afhankelijk van de grootte van de tekst.
Is het mogelijk om rapporten voor te bereiden en te downloaden via de API?
Ja, u kunt een PDF- of HTML-rapport downloaden zodra de plagiaatcontrole is voltooid. Alle rapporten worden in onze database opgeslagen, zodat u er op elk moment toegang toe hebt en kunt downloaden https://plagiarismsearch.com/docs/v3/reports/view
Kan ik mijn eigen rapportsjabloon maken?
Nee. We hebben 2 beschikbare rapportsjablonen. U kunt alleen het logo van uw bedrijf in ons rapportsjabloon plaatsen.
Staat de API toe om specifieke delen van de tekst te verifiëren?
Ja, als u het hebt over het opnemen of uitsluiten van referenties of citaten, of het op de witte lijst zetten van specifieke URL's.
Is het mogelijk om de geschiedenis van tekstcontroles via de API te bekijken?
Ja, alle rapporten worden in uw database opgeslagen.
Is het een REST API of plug-in? Is het synchroon of asynchroon?
Wij bieden een RESTful API. Toegang tot onze API-documentatie is hier: https://plagiarismsearch.com/docs/
Onze API is asynchroon. Wanneer de plagiaatcontrole is voltooid, sturen we een web_hook naar de callback_url van de gebruiker (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Is er een handleiding voor het implementeren van de API?
Een meer uitgebreide schema van API-implementatie is als volgt:
- Registreer op onze website hier https://plagiarismsearch.com/nl/account/signup
- Zorg ervoor dat uw saldo actief is of meld u aan voor een gratis API-proef https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
- Ga naar Mijn Profiel - API-instellingen, en u ziet API-gebruiker en sleutel persoonlijk voor uw gebruik https://plagiarismsearch.com/nl/account/api
- Stuur een bestand of tekst voor
plagiaatcontrole met behulp van HTTP Basic Authentication https://plagiarismsearch.com/docs/v3/reports/create.
Hier is een voorbeeld in CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - U ontvangt een antwoord
met rapport-ID:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Onze detectie-engine start het plagiaatcontroleproces.
- Na voltooiing van de plagiaatcontrole stuurt het systeem een POST-web_hook naar de URL die aan het ingediende document is gekoppeld. Als de URL niet was aangegeven, stuurt het systeem een POST-web_hook naar de URL die aan het account van de gebruiker is gekoppeld.
- Er is een alternatieve manier om de status van de plagiaatcontrole te bekijken, hoewel dit niet door ons team wordt aanbevolen. Het is om de rapportstatus te monitoren https://plagiarismsearch.com/docs/v3/reports/status met bepaalde tijdsintervallen en te controleren of de rapportstatus
“Finished” (
status=2), “Error” (status=-10), of “Server error” (status=-11) - Wanneer het plagiaatcontroleproces is voltooid, kunt u gedetailleerde informatie opvragen met behulp van het rapport-ID. Een van de voorbeelden is hier te vinden: https://plagiarismsearch.com/docs/v3/reports/view
U kunt daarnaast de parameter `show_relations` specificeren om meer gegevens te krijgen.
Bijvoorbeeld,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // standaard
const RELATIONS_TREE = 1;
show_relations = -2 =>retourneert een lijst met bronnen gesorteerd op plagiaatpercentage. Zie`data.sources`veld in antwoordshow_relations = -1 =>retourneert alle rapportgegevens. Paragrafen, zinnen en bronnen met gemarkeerde tekst. Zie`data.paragraphs`veld in antwoordshow_relations = 1 =>retourneert alle rapportgegevens. Paragrafen, zinnen en bronnen met gemarkeerde tekst. Zie`data.paragraphs`veld in antwoord
Moeten scripts wachten op het resultaat van de plagiaattest of is er een callbackfunctie die later kan worden aangeroepen om het documentverwerkingsresultaat te krijgen?
Er is een callback-hook POST URL-verzoek dat we met de gebruiker verbinden. U kunt ook uw (aangepaste) callback_url aangeven in de instellingen wanneer u uw document indient ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Het rapport kan in verschillende formaten worden gedownload: (https://plagiarismsearch.com/docs/v3/reports/view) (Zie "Response")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // openbare pdf-rapport URL
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // openbare html-rapport URL
"files": [
{
// openbare EN pdf-rapport URL versie 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // openbare ES pdf-rapport URL versie 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // openbare PL pdf-rapport URL versie 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // openbare EN pdf-rapport URL versie 1 (huidig)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Hoe krijg ik een HTML-rapport?
Om een HTML-rapportlink te ontvangen, moet u een GET-verzoek sturen naar https://plagiarismsearch.com/api/v3/reports/{id} waar {id} de rapport-ID is waarvoor u een rapport wilt ontvangen. In “Response” data vindt u de rapportlink in het veld `data.link`. Ook vindt u in “Response” de ‘data.auth_key’ waarmee u 3 mogelijke varianten van HTML-rapporten kunt genereren.
Bijvoorbeeld, er zijn 3 mogelijke varianten van HTML-rapporten voor data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Bovendien kunt u rapportlinks genereren in 4 verschillende talen (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
U kunt vrij verschillende varianten van HTML-rapporten en talen combineren om een gewenst type rapport in een gekozen taal te ontvangen.
Een soortgelijk schema kan worden gebruikt om een PDF-rapport link te genereren (deze URL's zijn te zien in “Response” -> `data.files`).
Bijvoorbeeld:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Ik kan geen eindpunten/details vinden over hoe toegangstokens te genereren.
Het token zal in uw account staan nadat u zich registreert (https://plagiarismsearch.com/nl/account/api)
Het is noodzakelijk om dit te verzenden met HTTP Basic-authenticatie.
Php met CURL
// HTTP basic authenticatie
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Ik wil bestanden in DOCX, PDF en PPT toevoegen om te controleren. Is dat mogelijk?
U kunt bestanden in meerdere formaten bijvoegen: (https://plagiarismsearch.com/docs/v3/reports/create) bestandstring of upload bestand ter controle.
Daarnaast kunt u bestanden verzenden met de naam `file`
Bijvoorbeeld:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Hoe kan ik de lijst met URL's krijgen waar tekst is gevonden?
U moet show_relations=1 gebruiken of, als u alleen bronnen nodig hebt (links => percentage plagiaat), de route aanroepen (POST-methode) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (nu niet gedocumenteerd) en het veld `data.sources` gebruiken
Hoe kan ik mijn URL van deze lijst uitsluiten?
U kunt de route aanroepen (POST-methode) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (nu niet gedocumenteerd) na het controleren van het rapport met post-parameters
a) POST['url'] = 'https://wikipedia.org' of
b) POST['source'] = {source.id} (bijvoorbeeld data.sources[0].id (integer)) of
c) array van overgeslagen URL's
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array van overgeslagen source-id's
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Als u de route twee keer aanroept - worden URL's weer opgenomen, wat het algemene plagiaatpercentage beïnvloedt
Voor een transparanter gebruik is het beter om routes te gebruiken met dezelfde parameters als hierboven beschreven.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
We zijn ook van plan een functie te voltooien waarmee u een URL hier kunt uitsluiten: https://plagiarismsearch.com/api/v3/reports/create
Hoe kan ik het plagiaatpercentage opnieuw berekenen na uitsluiting?
De reactie op het verzoek bevat het algemene (aangepaste) percentage plagiaat data.plagiat
Waar zijn "filter_references" & "filter_quotes" goed voor?
filter_references=1 => verwijder referenties. Referentietekst heeft geen invloed op het totale plagiaatpercentage
filter_quotes=1 => verwijder citaten in de tekst. Citaten tellen niet mee voor het totale plagiaatpercentage. Citatietekens zijn
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Is er een manier om de API via CURL te implementeren?
Hier zijn de richtlijnen die uw CURL-implementatie kunnen vereenvoudigen.
- Upload document voor plagiaatcontrole https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
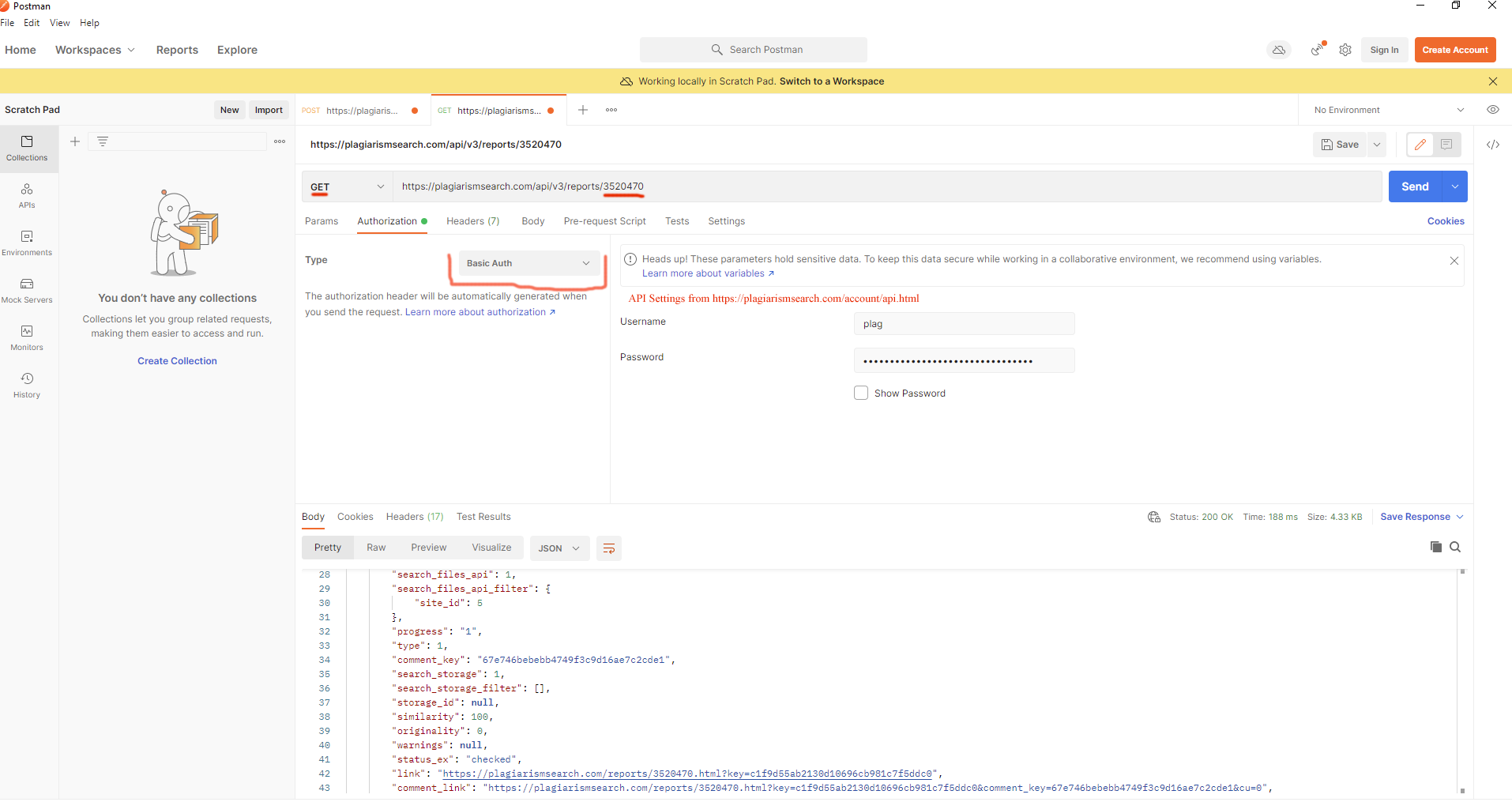
- Bekijk rapport https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Waarom heeft het document de status “Pending” in Storage?
Het document blijft meestal niet lang in de status Pending, van 0 tot 6 minuten nadat het is geüpload of opnieuw geüpload. Het document wordt onmiddellijk toegevoegd aan de zoekindex.
U kunt het ook controleren in de programmacode: als er 6 minuten zijn verstreken, heeft het document de status Actief.
Het is mogelijk om de documentstatus te achterhalen met deze methode:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Zie het veld `data.is_in_index`
Hoe documenten uploaden naar de storage via API?
U kunt uw documenten uploaden via API:
POST https://plagiarismsearch.com/api/v3/storage/create
met parameters die vergelijkbaar zijn met https://plagiarismsearch.com/docs/v3/reports/create
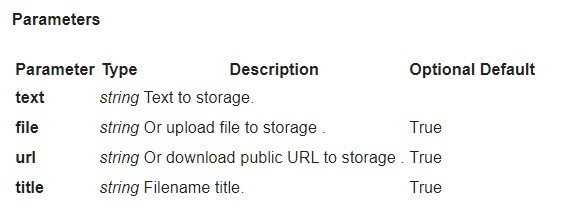
U kunt documenten ook in een lijst of een archief uploaden via het formulier https://plagiarismsearch.com/storage/upload
Wat zijn de mogelijkheden van een reseller-account? Hoe integreer ik het in mijn eigen systeem?
De functionaliteiten die ons reseller-account biedt, zijn:
- Elke nieuwe gebruiker moet via de API worden aangemaakt (u heeft login en wachtwoord nodig om elk gebruikersaccount aan te maken)
- U heeft de mogelijkheid om een bepaald aantal woorden toe te kennen aan elke gebruiker via het reseller-account.
Deze opties geven elke klant de mogelijkheid om zijn/haar account onafhankelijk te gebruiken, en u kunt woorden toevoegen die nodig zijn voor elke gebruiker
Technische documentatie nodig voor integratie:
U moet een reseller-account hebben
om klanten te kunnen aanmaken. Neem contact met ons op via services@plagiarismsearch.com om
toegang te krijgen tot alle mogelijkheden van een reseller-account.
Klant aanmaken
Om een nieuwe klant aan te maken, stuur een POST-verzoek https://plagiarismsearch.com/api/v3/reseller-customers/create (E-mail van de klant is een verplicht veld)
Bijvoorbeeld:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Respons
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}Lijst van klanten
Stuur een GET-verzoek 'https://plagiarismsearch.com/api/v3/reseller-customers' om de lijst te ontvangen van alle klanten die zijn aangemaakt.
Bijvoorbeeld:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Toon saldi
Stuur een GET-verzoek naar https://plagiarismsearch.com/api/v3/reseller-customers/balance om uw saldo te bekijken.
Bekijk uw saldo
Stuur een GET-verzoek naar https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} om het saldo van een specifieke klant te bekijken.
Voorbeeld van een saldo-respons:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Betalen naar het saldo van de klant
Voeg het benodigde aantal inzendingen of woorden toe aan het account van een specifieke klant door de gebruikers-ID en het bedrag in te voeren in het veld `words` of `submissions` (1 inzending = 1000 woorden).
Bijvoorbeeld:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
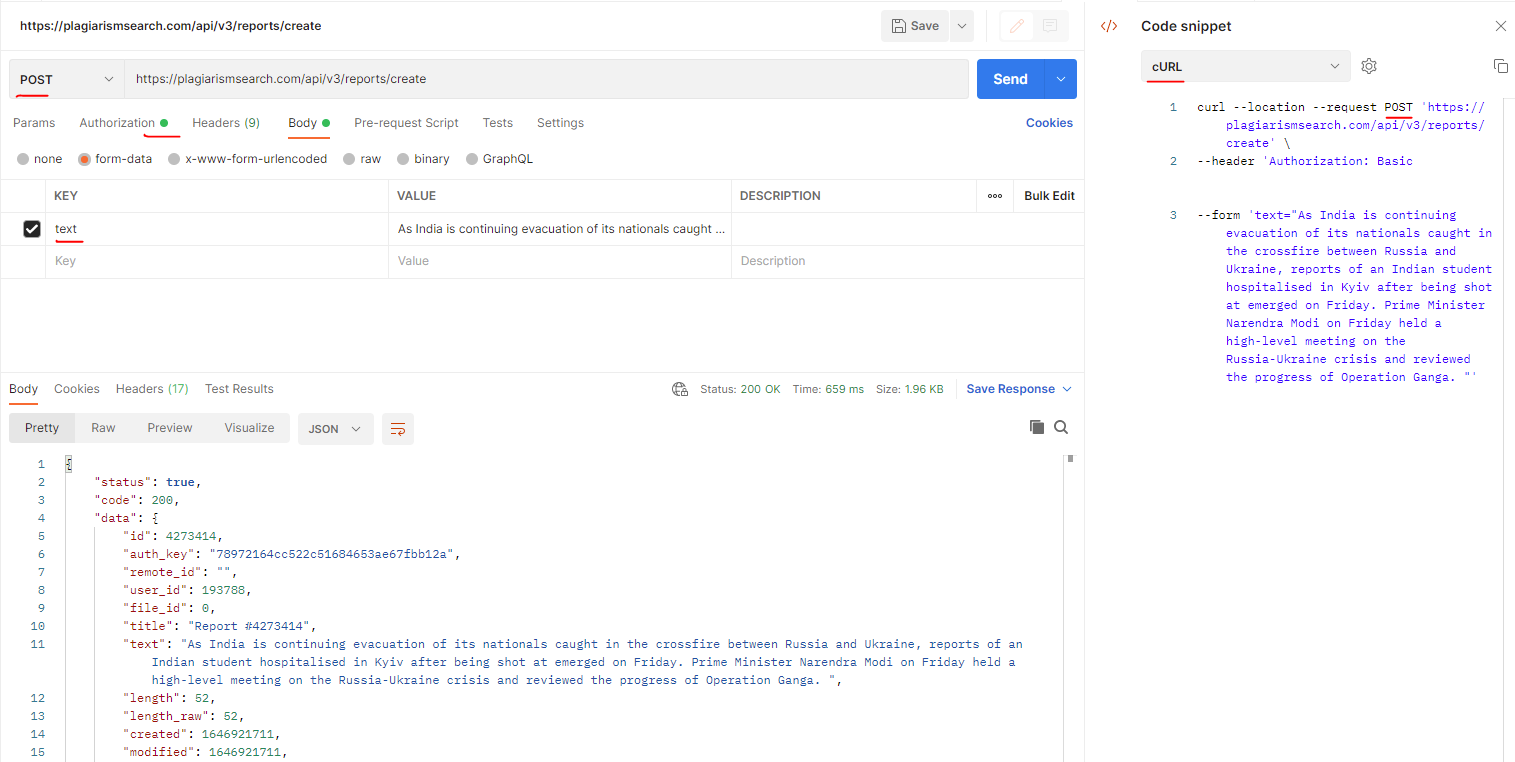
}Hoe corrigeer ik Fout: 400 Bad Request bij het indienen van tekst voor plagiaat?
De voorbeeldfout die u kunt krijgen bij het indienen van tekst voor plagiaat ziet er zo uit:
Request Method: PUT
Status Code: 400 Bad Request
Response: No instances available for plagiarismsearch.com
Gebruikte Plagiaat-API: https://plagiarismsearch.com/api/v3/reports/create
Oplossing:
De klant moet de POST Http-methode gebruiken (niet PUT) zoals op de screenshot
Er is een authenticatiefout terwijl ik de /report op GET uitvoer met het request-module in Python.
U moet de gegevens voor authenticatie bij elk nieuw verzoek verzenden.
We gebruiken Basic Authentication, zoals< https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// HTTP basisauthenticatie Php met CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);