PlagiarismSearch API : Questions et Réponses

API (interface de programmation d'application) est un ensemble de routines, protocoles et outils pour créer des applications logicielles. Elle est conçue pour aider les organisations à vérifier de grandes quantités de texte via leur système. Notre API offre aux clients une opportunité unique d'intégrer notre logiciel dans leurs propres systèmes pour automatiser le processus de vérification du plagiat. Puisque l'intégration de l'API nécessite des connaissances spécifiques et est généralement réalisée par des spécialistes techniques, de nombreuses questions surgissent concernant ses fonctionnalités spécifiques pour assurer un fonctionnement efficace. Dans cet article, nous avons rassemblé les questions-réponses les plus populaires sur la performance de notre API, ainsi que des solutions aux problèmes les plus fréquents rencontrés par nos clients lors du processus d'intégration.
De plus, l'intégration de l'API permet à nos clients de profiter du stockage personnel. Les clients peuvent télécharger leurs propres archives dans le système de stockage et sauvegarder les textes vérifiés pour plagiat via notre API, créant ainsi un stockage individuel. Vérifier les textes pour plagiat par rapport au stockage personnel permet à nos clients de détecter et prévenir l'auto-plagiat. En savoir plus sur les fonctionnalités du stockage personnel dans notre guide https://plagiarismsearch.com/plagiarism-database.
Quelles fonctionnalités sont disponibles via l'API ?
- Vérification des textes et des documents pour plagiat
- Accès aux rapports de plagiat (historique des vérifications de plagiat)
- Possibilité de télécharger la base de données du client dans le stockage et de consulter les documents dans le stockage
- Les revendeurs ont la possibilité de créer plusieurs comptes utilisateur et de leur attribuer le nombre approprié de soumissions/mots. Ces options permettront à chaque référence d'utiliser son compte de manière indépendante.
Comment puis-je accéder à l'API ?
Vous pouvez avoir accès à notre API gratuitement pendant 30 jours. Vous aurez également 100 soumissions et un stockage personnel pour tester tous les avantages de notre service. Veuillez vous inscrire en utilisant ce lien pour accéder à l'API gratuite : https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
Après votre inscription, allez dans Mon Profil - Paramètres API, et vous verrez l'utilisateur API et la clé fournis personnellement pour votre utilisation. Vous devrez également utiliser notre documentation API (cliquez sur la section documentation API https://plagiarismsearch.com/docs/ dans votre profil pour la consulter). Fournissez les informations ci-dessus à votre spécialiste technique pour commencer à utiliser notre API.
Comment fonctionne l'API de vérification du plagiat ?
Le schéma de fonctionnement de notre API est le suivant :
- L'utilisateur crée un rapport (en soumettant un texte, en téléchargeant un fichier ou une URL publique) https://plagiarismsearch.com/docs/v3/reports/create
- Si votre solde est actif – votre document est ajouté pour vérification
- Si vous vérifiez 1000-3000 mots en une fois, cela peut prendre 30-60 secondes ; plus de mots prennent un peu plus de temps
- Après vérification du document, l'utilisateur reçoit une requête POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- Exemple d'utilisation de l'API en PHP https://plagiarismsearch.com/files/sample-api.zip
L'API garantit-elle une vérification automatique des textes en temps réel ?
Oui, le processus de vérification du plagiat est effectué en temps réel. Cela prend 1-5 minutes pour vérifier un texte, le temps de vérification du plagiat dépend de la taille du texte.
Est-il possible de préparer et télécharger des rapports via l'API ?
Oui, vous pouvez télécharger un rapport PDF ou HTML dès que la vérification du plagiat est terminée. Tous les rapports sont stockés dans notre base de données, vous pouvez donc y accéder à tout moment et les télécharger https://plagiarismsearch.com/docs/v3/reports/view
Est-il possible de créer mon propre modèle de rapport ?
Non. Nous avons 2 modèles de rapport disponibles. Vous pouvez uniquement insérer le logo de votre entreprise dans notre modèle de rapport.
L'API permet-elle la vérification de parties spécifiques du texte ?
Oui, si vous souhaitez inclure ou exclure des références ou des citations, ou établir une liste blanche pour certaines URL.
Est-il possible de consulter l'historique des vérifications de texte via l'API ?
Oui, tous les rapports sont enregistrés dans votre base de données.
S'agit-il d'une API REST ou d'un plugin ? Est-elle synchrone ou asynchrone ?
Nous fournissons une API RESTful. L'accès à notre documentation API est ici : https://plagiarismsearch.com/docs/
Notre API est asynchrone. Lorsque la vérification de plagiat est terminée, nous envoyons un web_hook à l'URL de rappel de l'utilisateur (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Existe-t-il des instructions pour implémenter l'API ?
Un schéma plus détaillé de l'implémentation de l'API est le suivant :
- Inscrivez-vous sur notre site ici https://plagiarismsearch.com/account/signup
- Assurez-vous que votre solde est actif ou inscrivez-vous pour un essai gratuit de l'API https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
- Allez dans Mon Profil - Paramètres de l'API, et vous verrez l'Utilisateur API et la Clé fournie personnellement pour votre usage https://plagiarismsearch.com/account/api
- Envoyez un fichier ou un texte pour
la vérification de plagiat en utilisant l'authentification de base HTTP https://plagiarismsearch.com/docs/v3/reports/create.
Voici un exemple en CURL :
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Vous recevrez une réponse
avec l'ID du rapport :
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Notre moteur de détection commence le processus de vérification de plagiat.
- Une fois la vérification de plagiat terminée, le système envoie un web_hook POST à l'URL liée au document soumis. Si l'URL n'a pas été indiquée, le système envoie un web_hook POST à l'URL liée au compte de l'utilisateur.
- Il existe une méthode alternative pour connaître
l'état de la vérification de plagiat, bien que notre équipe ne la recommande pas. Elle consiste à surveiller
l'état du rapport https://plagiarismsearch.com/docs/v3/reports/status
à des intervalles de temps définis, et à vérifier si l'état du rapport est
“Terminé” (
status=2), “Erreur” (status=-10), ou “Erreur serveur” (status=-11) - Une fois le processus de vérification de plagiat terminé, vous pouvez obtenir des informations détaillées en utilisant l'ID du rapport. Un exemple se trouve ici : https://plagiarismsearch.com/docs/v3/reports/view
Vous pouvez également spécifier le paramètre `show_relations` pour obtenir plus de données.
Par exemple,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // par défaut
const RELATIONS_TREE = 1;
show_relations = -2 =>retourne la liste des sources classées par pourcentage de plagiat. Voir le champ de réponse`data.sources`show_relations = -1 =>retourne toutes les données du rapport. Paragraphes, phrases et sources avec le texte en surbrillance. Voir le champ de réponse`data.paragraphs`show_relations = 1 =>retourne toutes les données du rapport. Paragraphes, phrases et sources avec le texte en surbrillance. Voir le champ de réponse`data.paragraphs`
Les scripts doivent-ils attendre le résultat du test de plagiat ou existe-t-il une fonction de rappel qui peut être appelée ultérieurement pour obtenir le résultat du traitement du document ?
Il existe une requête POST d'URL de rappel connectée à l'utilisateur. Vous pouvez également indiquer votre propre callback_url dans les paramètres lorsque vous soumettez votre document ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Le rapport peut être téléchargé dans plusieurs formats : (https://plagiarismsearch.com/docs/v3/reports/view) (Voir "Réponse")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL publique du rapport PDF
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL publique du rapport HTML
"files": [
{
// URL publique du rapport PDF version 3 EN
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // URL publique du rapport PDF version 3 ES
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // URL publique du rapport PDF version 3 PL
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // URL publique du rapport PDF version 1 (actuelle)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Comment obtenir un rapport HTML ?
Pour recevoir un lien vers le rapport HTML, vous devez envoyer une requête GET à https://plagiarismsearch.com/api/v3/reports/{id}, où {id} est l'identifiant du rapport que vous souhaitez recevoir. Dans les données de la « Réponse », vous trouverez le lien du rapport dans le champ `data.link`. Également, dans la « Réponse », vous trouverez « data.auth_key » avec lequel vous pouvez générer 3 variantes possibles de rapports HTML.
Par exemple, il existe 3 variantes possibles de rapports HTML pour data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
De plus, vous pouvez générer des liens de rapport dans 4 langues différentes (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Vous êtes libre de combiner différentes variantes de rapports HTML et de langues pour recevoir le type de rapport souhaité dans la langue de votre choix.
Un schéma similaire peut être utilisé pour générer un lien vers le rapport PDF (ces URL peuvent être consultées dans la « Réponse » -> `data.files`).
Par exemple :
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Je ne parviens pas à trouver les points de terminaison/détails sur la génération des jetons d'accès.
Le jeton sera dans votre compte après votre inscription (https://plagiarismsearch.com/account/api)
Il est nécessaire de le transmettre en utilisant l'authentification HTTP basique.
Php avec CURL
// Authentification HTTP basique
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Je souhaite joindre des fichiers en DOCX, PDF et PPT pour vérification. Est-ce possible ?
Vous pouvez joindre des fichiers dans plusieurs formats : (https://plagiarismsearch.com/docs/v3/reports/create) fichier en chaîne ou téléverser un fichier pour vérification.
De plus, vous pouvez envoyer des fichiers avec le nom `file`
Par exemple :
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Comment puis-je obtenir la liste des URL où le texte a été trouvé ?
Vous devez utiliser show_relations=1 ou, si vous avez besoin uniquement des sources (liens => pourcentage de plagiat), appeler la route (méthode POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (non documenté pour l'instant) et utiliser le champ `data.sources`
Comment puis-je exclure mon URL de cette liste ?
Vous pouvez appeler la route (méthode POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (non documenté pour l'instant) après la vérification du rapport avec les paramètres de poste
a) POST['url'] = 'https://wikipedia.org' ou
b) POST['source'] = {source.id} (par exemple, data.sources[0].id (entier)) ou
c) tableau des URLs ignorées
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
tableau des IDs de sources ignorées
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Si vous appelez la route deux fois, les URLs seront à nouveau incluses, influençant le pourcentage général de plagiat.
Pour une utilisation plus transparente, il est préférable d'utiliser les routes avec les mêmes paramètres décrits ci-dessus.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Nous prévoyons également de compléter un ensemble de fonctionnalités permettant d'exclure l'URL ici : https://plagiarismsearch.com/api/v3/reports/create
Comment recalculer le pourcentage de plagiat après exclusion ?
La réponse à la requête inclura le pourcentage général (modifié) de plagiat data.plagiat
À quoi servent "filter_references" et "filter_quotes" ?
filter_references=1 => exclure les références. Le texte des références n'a aucun impact sur le pourcentage total de plagiat
filter_quotes=1 => exclure les citations. Le texte des citations n'a aucun impact sur le pourcentage total de plagiat. Les marqueurs de citation sont
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Y a-t-il un moyen d'implémenter l'API via CURL ?
Voici des directives qui pourraient faciliter votre implémentation CURL.
- Charger un document pour vérification de plagiat https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic votre_clé_utilisateur==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Voir le rapport https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic votre_clé_utilisateur=='

Pourquoi le document a-t-il le statut “En attente” dans le stockage ?
Le document reste généralement en statut En attente pour une courte durée, de 0 à 6 minutes après son téléchargement ou son re-téléchargement. Le document est instantanément ajouté à l'index de recherche.
Vous pouvez également le vérifier dans le code du programme : si 6 minutes se sont écoulées, le document a le statut Actif.
Il est possible de connaître le statut du document en utilisant la méthode suivante :
GET https://plagiarismsearch.com/api/v3/storage/{id}
Voir le champ `data.is_in_index`
Comment charger des documents dans le stockage via l'API ?
Vous pouvez télécharger vos documents via l'API :
POST https://plagiarismsearch.com/api/v3/storage/create
avec des paramètres similaires à https://plagiarismsearch.com/docs/v3/reports/create
Vous pouvez également télécharger des documents sous forme de liste ou d'archive en utilisant le formulaire https://plagiarismsearch.com/storage/upload
Quelles sont les possibilités d'un compte revendeur ? Comment l'intégrer dans mon propre système ?
Les fonctionnalités offertes par notre compte revendeur sont :
- Chaque nouvel utilisateur doit être créé via l'API (un identifiant et un mot de passe sont nécessaires pour créer chaque compte utilisateur)
- Vous aurez la possibilité d'attribuer un nombre particulier de mots pour chaque utilisateur via le compte revendeur.
Ces options permettront à chaque client d'utiliser son compte de manière indépendante, et vous pourrez ajouter les mots nécessaires pour chaque utilisateur
Documentation technique nécessaire pour l'intégration :
Vous devez avoir un type de compte revendeur
pour pouvoir créer des clients. Contactez-nous à services@plagiarismsearch.com pour
accéder aux fonctionnalités complètes d'un compte revendeur.
Créer un client
Pour créer un nouveau client, envoyez une requête POST https://plagiarismsearch.com/api/v3/reseller-customers/create (L'e-mail du client est un champ obligatoire)
Par exemple :
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
votre_clé_utilisateur===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="Nom de l'utilisateur"' \
--form 'password="123456"'
Réponse
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"Nom de l'utilisateur",
"status":"actif",
"password":"123456"
},
"version":"3.0.0"
}Liste des clients
Envoyez une requête GET 'https://plagiarismsearch.com/api/v3/reseller-customers' pour recevoir la liste de tous les clients qui ont été créés.
Par exemple :
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Afficher les soldes
Envoyez une requête GET https://plagiarismsearch.com/api/v3/reseller-customers/balance pour consulter votre solde.
Obtenez votre solde
Envoyez une requête GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} pour consulter le solde d'un client particulier.
Exemple de réponse de solde :
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Mots",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Soumissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Payer au solde du client
Ajoutez le nombre nécessaire de soumissions ou de mots au compte d'un client particulier en saisissant l'ID de l'utilisateur et en entrant le montant dans le champ `words` ou `submissions` (1 soumission = 1000 mots).
Par exemple :
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Mots"
},
"version":"3.0.0"
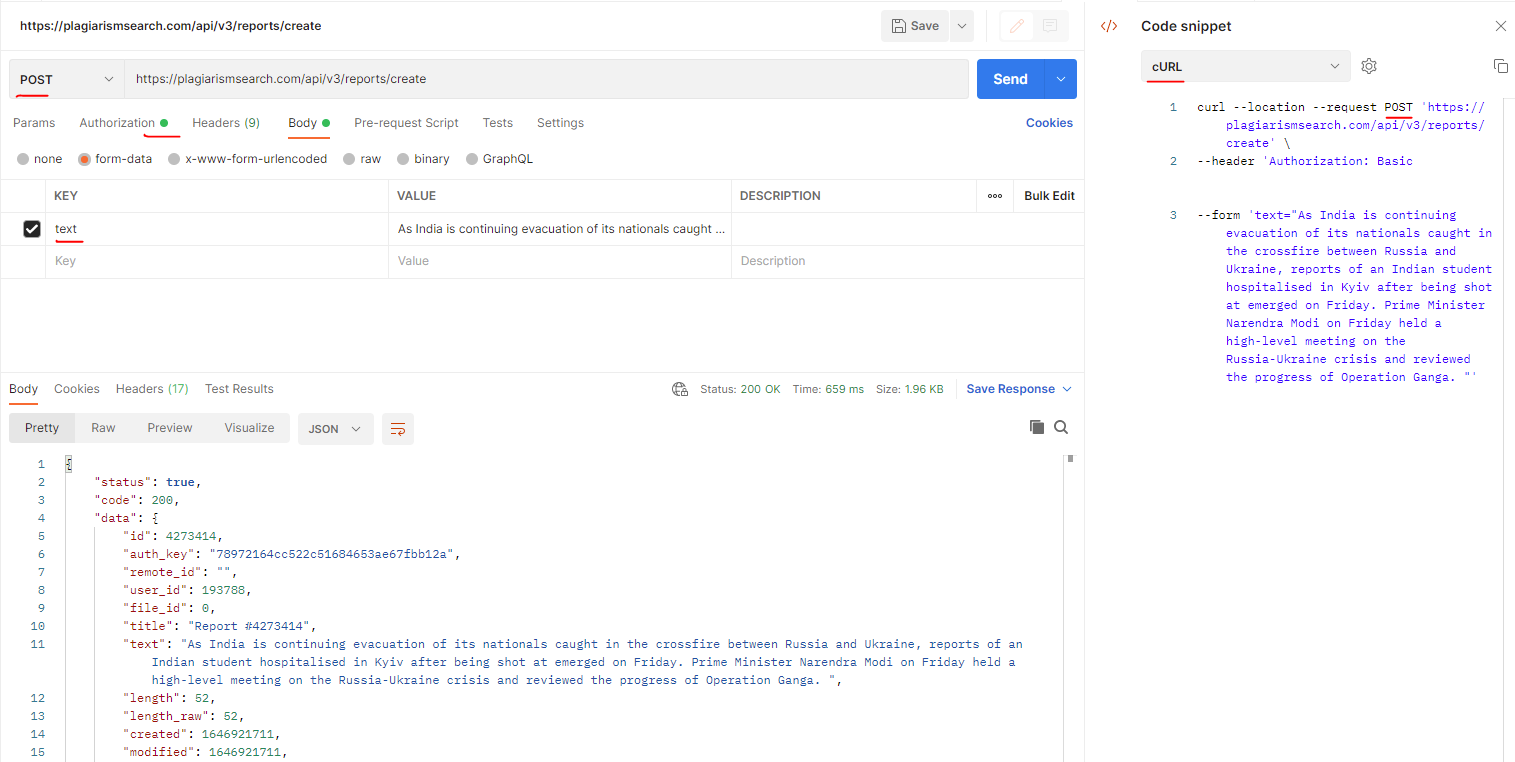
}Comment corriger l'erreur : 400 Bad Request lors de la soumission de texte pour vérification de plagiat ?
L'exemple d'erreur que vous pouvez obtenir lors de la soumission de texte pour vérification de plagiat pourrait ressembler à :
Méthode de requête : PUT
Code d'état : 400 Bad Request
Réponse : Aucune instance disponible pour plagiarismsearch.com
Plagiarism API utilisée : https://plagiarismsearch.com/api/v3/reports/create
Solution :
Le client doit utiliser la méthode POST (pas PUT) comme sur la capture d'écran
Il y a une erreur d'authentification lorsque j'exécute le /report sur GET en utilisant le module request en Python.
Vous devez envoyer les données concernant l'authentification à chaque nouvelle requête.
Nous utilisons l'authentification de base, comme décrit ici : https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Authentification HTTP de base Php avec CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);