PlagiarismSearch API: Questions and Answers

API (Application programming interface) is a set of routines, protocols, and tools for building software applications. It is created to help organizations to check large amounts of text through their system. Our API gives the customers a unique opportunity to integrate our software into their own systems to make plagiarism check an automated process. Since the API integration requires specific knowledge and is usually completed by technical specialists, many questions arise about its particular features to ensure efficient operation. In the article we gathered the most popular questions-answers about our API performance, and solutions to the most frequent problems that our customers face during the process of integration.
Additionally, the API integration gives our clients an opportunity to take advantage of the personal Storage. Customers may upload their own archives into the Storage system and save the texts checked for plagiarism through our API, thus creating an individual Storage. Checking texts for plagiarism against the personal Storage allows our customers to detect and prevent self-plagiarism. Read more about the functionalities of the personal storage in our guide https://plagiarismsearch.com/plagiarism-database.
What features are available through the API?
- Checking texts and document for plagiarism
- Access to plagiarism reports (history of plagiarism checks)
- Ability to upload client’s database into the storage and view the documents in the storage
- Resellers have the opportunity to create multiple user accounts and assign them with appropriate number of submissions/words. These options will give the possibility for each referral to use his/her account independently.
How can I get access to the API?
You can have access to our API for free for 30 days. You will also have 100 submissions and personal Storage to test all the benefits of our service. Please register using this link to receive access to free API: https://plagiarismsearch.com/de/account/signup?from=%2Faccount%2Fapi
After you register, go to My Profile - API Settings, and you will see API User and Key provided personally for your use. Also, you will need to use our API documentation (click on API documentation section https://plagiarismsearch.com/docs/ in Your Profile to view it). Provide access to the above information for your technical specialist to start using our API.
How Does the plagiarism check API work?
The scheme of our API operation is as follows:
- The user creates a report (by submitting a text, uploading a file, or a public URL) https://plagiarismsearch.com/docs/v3/reports/create
- If your balance is active – your document is added for checking
- If you check 1000-3000 words at once, it can take 30-60 seconds; more words take slightly longer
- After checking the document, the user gets a`callback_url` POST request https://plagiarismsearch.com/docs/v3/reports/callback-request
- The sample of the API usage at PHP https://plagiarismsearch.com/files/sample-api.zip
Does the API ensure automatic text verification in real time?
Yes, the plagiarism check process is performed in real time. It takes 1-5 minutes to check a text, the time of plagiarism check depends on the size of the text.
Is it possible to prepare and download reports through the API?
Yes, you can download PDF or HTML report right after plagiarism check is completed. All reports are stored in our database, so you can access them at any time and download https://plagiarismsearch.com/docs/v3/reports/view
Is it possible to create my own report template?
No. We have 2 available report templates. You can only insert your company's logo into our report template.
Does the API enable specific parts of the text verification?
Yes, if you are talking about including or excluding references or citations, whitelisting particular URLs.
Is it possible to view the history of text checking through the API?
Yes, all reports are saved in your database.
Is it REST API or plugin? Is it synchronous or asynchronous?
We provide RESTful API. The access to our API documentation is here: https://plagiarismsearch.com/docs/
Our API is asynchronous. When the plagiarism check is finished, we send a web_hook to user callback_url (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Is there any instruction on how to implement the API?
A more elaborate scheme of API implementation is as follows:
- Register with our website here https://plagiarismsearch.com/de/account/signup
- Make sure your balance is active or sign up for a free API trial https://plagiarismsearch.com/de/account/signup?from=%2Faccount%2Fapi
- Go to My Profile - API Settings, and you will see API User and Key provided personally for your use https://plagiarismsearch.com/de/account/api
- Send a file or text for
plagiarism check using HTTP basic authentication https://plagiarismsearch.com/docs/v3/reports/create.
Here is an example in CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - You will receive a response
with report ID:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Our detection engine starts plagiarism check process.
- After the plagiarism check is completed, the system sends POST web_hook to the URL that is linked to the submitted document. In case the URL was not indicated, the system sends POST web_hook to the URL that is linked to the user’s account.
- There an alternative way to set
the status of plagiarism check, though, not recommended by our team. It is to monitor
the report status https://plagiarismsearch.com/docs/v3/reports/status
Wie kann ich meine URL aus dieser Liste ausschließen?
Sie können die Route (POST-Methode) aufrufen https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (derzeit nicht dokumentiert) nach der Berichtskontrolle mit den POST-Parametern
a)
POST['url'] = 'https://wikipedia.org'oderb)
POST['source'] = {source.id} (zum Beispiel data.sources[0].id (Ganzzahl))oderc) Array von übersprungenen URLs
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'Array von übersprungenen Quellen-IDs
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}Wenn Sie die Route zweimal aufrufen, werden die URLs wieder eingeschlossen, was den Gesamtanteil an Plagiaten beeinflusst
Für eine transparentere Nutzung ist es besser, Routen mit denselben Parametern wie oben beschrieben zu verwenden.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}Wir planen auch, ein Funktionsset zu vervollständigen, das es ermöglichen würde, URLs hier auszuschließen: https://plagiarismsearch.com/api/v3/reports/create
Wie kann ich den Plagiatsanteil nach dem Ausschluss neu berechnen?
Die Antwort auf die Anfrage enthält den allgemeinen (geänderten) Plagiatsanteil
data.plagiatWofür sind "filter_references" & "filter_quotes" gut?
filter_references=1 =>Schließt Referenzen aus. Der Text der Referenzen hat kein Gewicht für den Gesamtplagiatsanteilfilter_quotes=1 =>Schließt Zitate im Text aus. Der Text der Zitate hat kein Gewicht für den Gesamtplagiatsanteil. Zitatmarkierungen sindarray('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Gibt es eine Möglichkeit, die API über CURL zu implementieren?
Hier sind die Richtlinien, die Ihre CURL-Implementierung erleichtern könnten.
- Dokument für Plagiatsprüfung hochladen https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
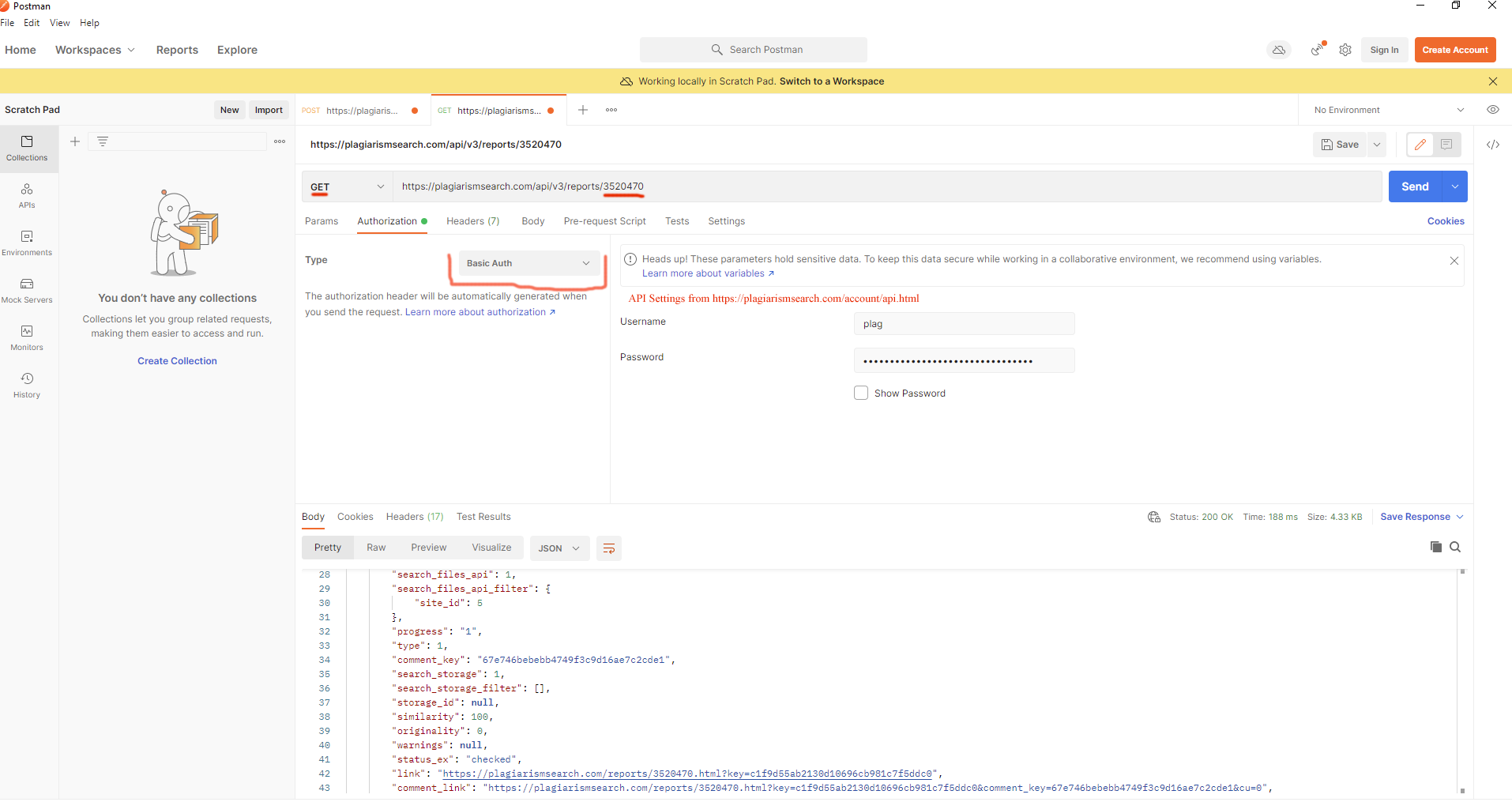
- Bericht anzeigen https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Warum hat das Dokument den Status "Pending" im Storage?
Das Dokument bleibt normalerweise nicht lange im Pending-Status, von 0 bis 6 Minuten, nachdem es hochgeladen oder erneut hochgeladen wurde. Das Dokument wird sofort dem Suchindex hinzugefügt.
Sie können es auch im Code des Programms überprüfen: Wenn 6 Minuten vergangen sind, hat das Dokument den Status "Aktiv".
Es ist möglich, den Dokumentstatus mit dieser Methode herauszufinden:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Siehe`data.is_in_index`FeldWie lade ich Dokumente über die API in den Storage hoch?
Sie können Ihre Dokumente über die API hochladen:
POST https://plagiarismsearch.com/api/v3/storage/create
mit Parametern, die denen von https://plagiarismsearch.com/docs/v3/reports/create ähnlich sind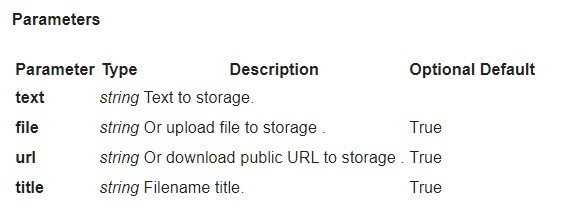
Alternativ können Sie Dokumente in einer Liste oder einer Archivdatei mit dem Formular https://plagiarismsearch.com/storage/upload hochladen
Was sind die Möglichkeiten eines Reseller-Kontos? Wie integriere ich es in mein eigenes System?
Die Funktionen, die durch unser Reseller-Konto angeboten werden, sind:
- Jeder neue Benutzer muss über die API erstellt werden (Sie benötigen einen Benutzernamen und ein Passwort, um jedes Benutzerkonto zu erstellen)
- Sie haben die Möglichkeit, eine bestimmte Anzahl von Wörtern für jeden Benutzer über das Reseller-Konto zu vergeben.
Diese Optionen ermöglichen es jedem Kunden, sein eigenes Konto unabhängig zu nutzen, und Sie können die für jeden Benutzer erforderlichen Wörter hinzufügen
Technische Dokumentation für die Integration:
Sie müssen ein Reseller-Konto haben, um Kunden erstellen zu können. Kontaktieren Sie uns unter services@plagiarismsearch.com
Kunden erstellen
Um einen neuen Kunden zu erstellen, senden Sie eine POST-Anfrage https://plagiarismsearch.com/api/v3/reseller-customers/create (Die Kunden-E-Mail ist ein Pflichtfeld)
Beispiel:
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="Benutzername"' \
--form 'password="123456"'Antwort
{ "status":true, "code":200, "data":{ "id":26784, "email":"testusermail@gmail.com", "name":"Benutzername", "status":"aktiv", "password":"123456" }, "version":"3.0.0" }Liste der Kunden
Schicken Sie eine GET-Anfrage 'https://plagiarismsearch.com/api/v3/reseller-customers', um die Liste aller erstellten Kunden zu erhalten.
Zum Beispiel:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='Guthaben anzeigen
Schicken Sie eine GET-Anfrage https://plagiarismsearch.com/api/v3/reseller-customers/balance um Ihr Guthaben anzuzeigen.
Ihr Guthaben abrufen
Schicken Sie eine GET-Anfrage https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} um das Guthaben eines bestimmten Kunden anzuzeigen.
Beispiel einer Guthaben-Antwort:
{ "status":true, "code":200, "data":{ "is_solvable":true, "700":{ "type":"Wörter", "amount":6001, "expired":1878542044, "is_valid":true, "is_solvable":true }, "300":{ "type":"Einreichungen", "amount":4, "expired":1720878480, "is_valid":true, "is_solvable":true } }, "version":"3.0.0" }Bezahlen Sie das Guthaben des Kunden
Fügen Sie die erforderliche Anzahl von Einreichungen oder Wörtern zum Konto eines bestimmten Kunden hinzu, indem Sie die Benutzer-ID eingeben und den Betrag im Feld 'Wörter' oder 'Einreichungen' angeben (1 Einreichung = 1000 Wörter).
Zum Beispiel:
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
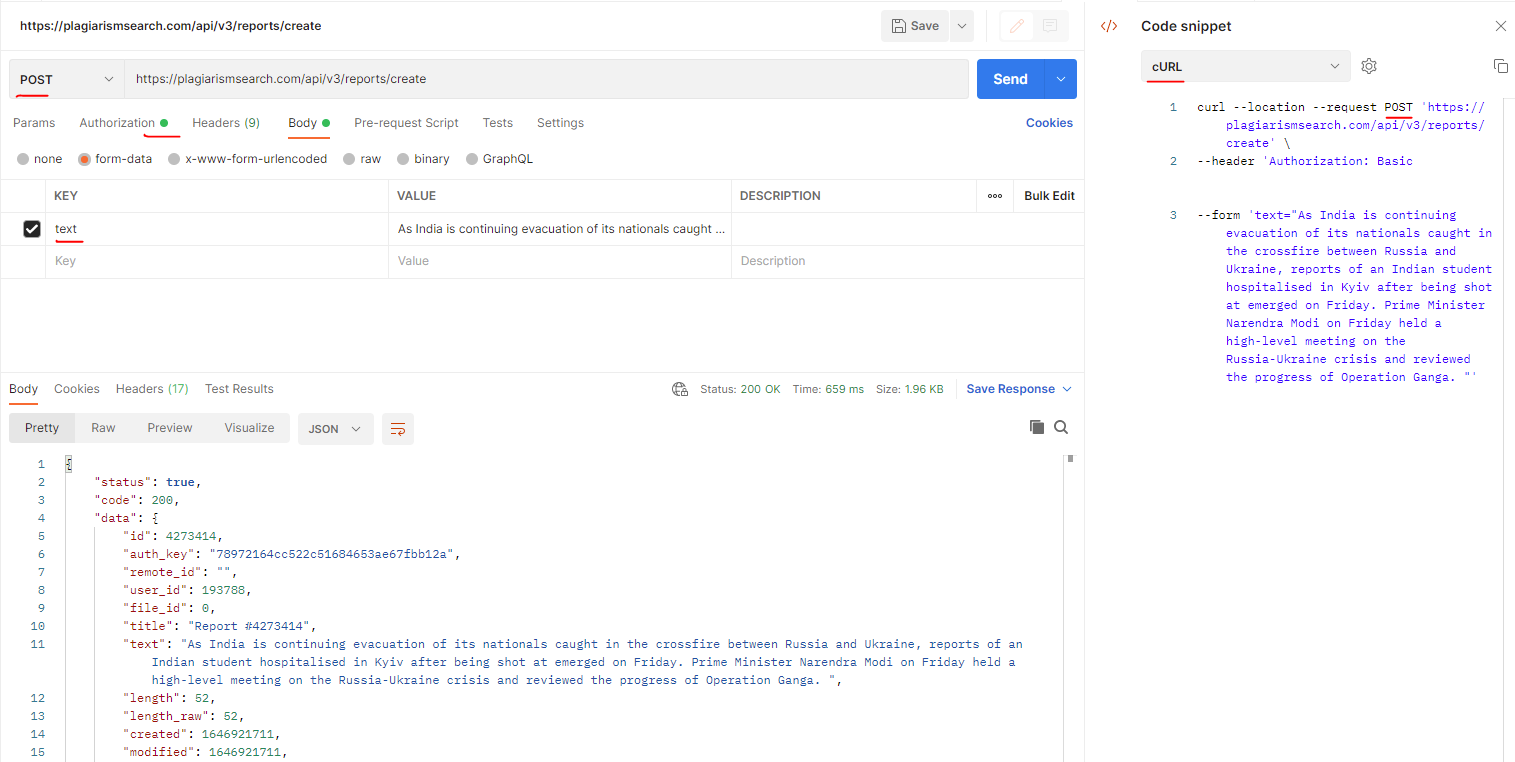
{ "status":true, "code":200, "data":{ "payment_id":1171, "amount":100, "type":"Wörter" }, "version":"3.0.0" }Wie man Fehler 400 Bad Request beim Einreichen von Text zur Plagiatsprüfung korrigiert?
Das Beispiel für den Fehler, den Sie möglicherweise erhalten, wenn Sie Text zur Plagiatsprüfung einreichen, könnte wie folgt aussehen:
Anfragemethode: PUT
Statuscode: 400 Bad RequestAntwort: Keine Instanzen verfügbar für plagiarismsearch.com
Verwendete Plagiats-API: https://plagiarismsearch.com/api/v3/reports/create
Lösung:
Der Kunde sollte die POST-Http-Methode verwenden (nicht PUT), wie im Screenshot
Es gibt einen Authentifizierungsfehler, während ich /report mit GET im Anfrage-Modul in Python ausführe.
Sie müssen die Daten zur Authentifizierung bei jeder neuen Anfrage senden.
Wir verwenden die Basis-Authentifizierung, wie unter https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// HTTP-Basis-Authentifizierung in Php mit CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
- Dokument für Plagiatsprüfung hochladen https://plagiarismsearch.com/docs/v3/reports/create