PlagiarismSearch API: Pytania i odpowiedzi

API (Interfejs programowania aplikacji) to zestaw procedur, protokołów i narzędzi do tworzenia aplikacji oprogramowania. Zostało stworzone, aby pomóc organizacjom sprawdzać duże ilości tekstu za pomocą ich systemu. Nasze API daje klientom unikalną możliwość integracji naszego oprogramowania z ich własnymi systemami, aby proces sprawdzania plagiatu stał się zautomatyzowany. Ponieważ integracja API wymaga specjalistycznej wiedzy i zazwyczaj jest realizowana przez specjalistów technicznych, pojawia się wiele pytań dotyczących jego szczególnych cech, aby zapewnić efektywne działanie. W artykule zebraliśmy najczęściej zadawane pytania-odpowiedzi dotyczące działania naszego API oraz rozwiązania najczęstszych problemów, z którymi nasi klienci spotykają się podczas procesu integracji.
Dodatkowo integracja API daje naszym klientom możliwość skorzystania z osobistego magazynu. Klienci mogą przesyłać swoje archiwa do systemu Storage i przechowywać teksty sprawdzone pod kątem plagiatu za pomocą naszego API, tworząc w ten sposób indywidualny magazyn. Sprawdzanie tekstów pod kątem plagiatu w porównaniu do osobistego magazynu pozwala naszym klientom wykrywać i zapobiegać plagiatowi własnemu. Przeczytaj więcej o funkcjonalnościach osobistego magazynu w naszym przewodniku https://plagiarismsearch.com/plagiarism-database.
Jakie funkcje są dostępne przez API?
- Sprawdzanie tekstów i dokumentów pod kątem plagiatu
- Dostęp do raportów plagiatu (historia sprawdzeń plagiatu)
- Możliwość przesyłania bazy danych klienta do magazynu i przeglądania dokumentów w magazynie
- Sprzedawcy mają możliwość tworzenia wielu kont użytkowników i przypisywania im odpowiedniej liczby zgłoszeń/słów. Te opcje umożliwiają każdemu użytkownikowi korzystanie ze swojego konta niezależnie.
Jak mogę uzyskać dostęp do API?
Możesz uzyskać dostęp do naszego API za darmo przez 30 dni. Będziesz także mieć 100 zgłoszeń i osobisty magazyn do przetestowania wszystkich korzyści z naszej usługi. Zarejestruj się, korzystając z tego linku, aby uzyskać dostęp do darmowego API: https://plagiarismsearch.com/pl/account/signup?from=%2Faccount%2Fapi
Po rejestracji przejdź do Mojego Profilu - Ustawienia API, a zobaczysz użytkownika API oraz klucz udostępniony specjalnie do Twojego użytku. Będziesz także potrzebować naszej dokumentacji API (kliknij na sekcję dokumentacji API https://plagiarismsearch.com/docs/ w swoim Profilu, aby ją zobaczyć). Udostępnij dostęp do powyższych informacji swojemu specjaliście technicznemu, aby rozpocząć korzystanie z naszego API.
Jak działa API sprawdzania plagiatu?
Schemat działania naszego API jest następujący:
- Użytkownik tworzy raport (poprzez przesłanie tekstu, załadowanie pliku lub publiczny URL) https://plagiarismsearch.com/docs/v3/reports/create
- Jeśli Twój bilans jest aktywny – Twój dokument zostaje dodany do sprawdzenia
- Jeśli sprawdzasz 1000-3000 słów naraz, może to zająć 30-60 sekund; większa liczba słów zajmuje nieco więcej czasu
- Po sprawdzeniu dokumentu użytkownik otrzymuje żądanie POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- Przykład użycia API w PHP https://plagiarismsearch.com/files/sample-api.zip
Czy API zapewnia automatyczne sprawdzanie tekstu w czasie rzeczywistym?
Tak, proces sprawdzania plagiatu odbywa się w czasie rzeczywistym. Sprawdzanie tekstu zajmuje 1-5 minut, czas sprawdzania zależy od rozmiaru tekstu.
Czy mogę przygotować i pobrać raporty przez API?
Tak, możesz pobrać raport PDF lub HTML bezpośrednio po zakończeniu sprawdzania plagiatu. Wszystkie raporty są przechowywane w naszej bazie danych, więc możesz uzyskać do nich dostęp w dowolnym momencie i pobrać je https://plagiarismsearch.com/docs/v3/reports/view
Czy mogę stworzyć własny szablon raportu?
Nie. Mamy 2 dostępne szablony raportów. Możesz jedynie dodać logo swojej firmy do naszego szablonu raportu.
Czy API umożliwia weryfikację określonych części tekstu?
Tak, jeśli chodzi o uwzględnianie lub wykluczanie odwołań lub cytatów, dodawanie do białej listy określonych adresów URL.
Czy możliwe jest wyświetlenie historii sprawdzania tekstu za pomocą API?
Tak, wszystkie raporty są zapisywane w Twojej bazie danych.
Czy to API REST czy plugin? Czy jest synchroniczne czy asynchroniczne?
Udostępniamy API typu RESTful. Dokumentacja API jest dostępna tutaj: https://plagiarismsearch.com/docs/
Nasze API jest asynchroniczne. Po zakończeniu sprawdzania plagiatu wysyłamy web_hook do callback_url użytkownika (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Czy istnieje instrukcja, jak zaimplementować API?
Bardziej szczegółowy schemat implementacji API wygląda następująco:
- Zarejestruj się na naszej stronie tutaj https://plagiarismsearch.com/pl/account/signup
- Upewnij się, że Twoje saldo jest aktywne lub zarejestruj się na darmowy okres próbny API https://plagiarismsearch.com/pl/account/signup?from=%2Faccount%2Fapi
- Przejdź do Moje konto - Ustawienia API, a zobaczysz Użytkownika API i Klucz przypisane do Twojego konta https://plagiarismsearch.com/pl/account/api
- Wyślij plik lub tekst do
sprawdzenia plagiatu za pomocą HTTP basic authentication https://plagiarismsearch.com/docs/v3/reports/create.
Oto przykład w CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Otrzymasz odpowiedź
z identyfikatorem raportu:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Nasza maszyna detekcyjna rozpocznie proces sprawdzania plagiatu.
- Po zakończeniu sprawdzania plagiatu system wysyła POST web_hook na adres URL powiązany z przesłanym dokumentem. Jeśli URL nie został wskazany, system wysyła POST web_hook na adres URL powiązany z kontem użytkownika.
- Istnieje alternatywna metoda ustawienia
statusu sprawdzania plagiatu, choć nie jest to zalecane przez nasz zespół. Należy monitorować
status raportu https://plagiarismsearch.com/docs/v3/reports/status
w określonych interwałach czasowych, aby sprawdzić, czy status raportu to
"Zakończono" (
status=2), "Błąd" (status=-10), lub "Błąd serwera" (status=-11) - Po zakończeniu procesu sprawdzania plagiatu możesz uzyskać szczegółowe informacje używając identyfikatora raportu. Jeden z przykładów znajduje się tutaj: https://plagiarismsearch.com/docs/v3/reports/view
Możesz dodatkowo określić parametr `show_relations`, aby uzyskać więcej danych.
Na przykład,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // domyślnie
const RELATIONS_TREE = 1;
show_relations = -2 =>zwróci listę źródeł posortowanych według procentu plagiatu. Zobacz pole odpowiedzi`data.sources`show_relations = -1 =>zwróci wszystkie dane raportu. Akapity, zdania i źródła z wyróżnionym tekstem. Zobacz pole odpowiedzi`data.paragraphs`show_relations = 1 =>zwróci wszystkie dane raportu. Akapity, zdania i źródła z wyróżnionym tekstem. Zobacz pole odpowiedzi`data.paragraphs`
Czy skrypty muszą czekać na wynik testu plagiatu, czy jest dostępna funkcja callback, która może być wywołana później w celu uzyskania wyniku przetwarzania dokumentu?
Istnieje żądanie URL POST callback, które łączymy z użytkownikiem. Możesz również wskazać swój (niestandardowy) callback_url w ustawieniach podczas przesyłania dokumentu ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Raport można pobrać w kilku formatach: (https://plagiarismsearch.com/docs/v3/reports/view) (Zobacz "Odpowiedź")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // publiczny URL raportu PDF
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // publiczny URL raportu HTML
"files": [
{
// publiczny EN URL raportu PDF wersja 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // publiczny ES URL raportu PDF wersja 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // publiczny PL URL raportu PDF wersja 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // publiczny EN URL raportu PDF wersja 1 (aktualna)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Jak uzyskać raport HTML?
Aby otrzymać link do raportu HTML, musisz wysłać zapytanie GET https://plagiarismsearch.com/api/v3/reports/{id} gdzie {id} to identyfikator raportu, dla którego chcesz otrzymać raport. W polu „Response” znajdziesz link do raportu w polu `data.link`. Ponadto, w „Response” znajdziesz ‘data.auth_key’, którego możesz użyć do wygenerowania 3 możliwych wersji raportów HTML.
Na przykład, istnieją 3 możliwe warianty raportów HTML dla data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Dodatkowo możesz wygenerować linki do raportów w 4 różnych językach (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Możesz dowolnie łączyć różne warianty raportów HTML i języków, aby uzyskać odpowiedni typ raportu w wybranym języku.
Podobny schemat może być użyty do generowania linku raportu PDF (te URL mogą być wyświetlane w „Response” -> `data.files`).
Na przykład:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Nie mogę znaleźć punktów końcowych/detali dotyczących generowania tokenów dostępu.
Token będzie dostępny w Twoim koncie po rejestracji (https://plagiarismsearch.com/pl/account/api)
Musisz go przesłać za pomocą autentykacji HTTP basic.
Php z CURL
// autentykacja HTTP basic
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
Chciałbym załączyć pliki w formatach DOCX, PDF i PPT do sprawdzenia. Czy to możliwe?
Możesz załączyć pliki w wielu formatach: (https://plagiarismsearch.com/docs/v3/reports/create) ciąg pliku lub przesłać plik do sprawdzenia.
Ponadto, możesz wysłać pliki o nazwie `file`
Na przykład:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Jak mogę uzyskać listę URL-i, w których znaleziono tekst?
Musisz użyć show_relations=1 lub jeśli potrzebujesz tylko źródeł (linki => procent plagiatu) lub wywołać trasę (metoda POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (teraz niedokumentowane) i użyć pola `data.sources`
Jak mogę wykluczyć mój URL z tej listy?
Możesz wywołać trasę (metoda POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (teraz niedokumentowane) po sprawdzeniu raportu z parametrami POST
a) POST['url'] = 'https://wikipedia.org' lub
b) POST['source'] = {source.id} (na przykład data.sources[0].id (liczba całkowita)) lub
c) tablica pominiętych URL-i
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
tablica pominiętych identyfikatorów źródeł
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Jeśli wywołasz trasę dwukrotnie - URL-e zostaną ponownie uwzględnione, co wpłynie na ogólny procent plagiatu
Dla bardziej przejrzystego użycia, lepiej jest używać tras z tymi samymi parametrami, które zostały opisane powyżej.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Planujemy również dodać funkcję, która pozwoli na wykluczenie URL-a tutaj: https://plagiarismsearch.com/api/v3/reports/create
Jak mogę przeliczyć procent plagiatu po wykluczeniu?
Odpowiedź na zapytanie będzie zawierała ogólny (zmieniony) procent plagiatu data.plagiat
Do czego służą "filter_references" i "filter_quotes"?
filter_references=1 => wyklucza odniesienia. Tekst odniesień nie ma wpływu na całkowity procent plagiatu
filter_quotes=1 => wyklucza cytaty w tekście. Tekst cytatów nie ma wpływu na całkowity procent plagiatu. Wskaźniki cytatów to
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Czy istnieje sposób na implementację API za pomocą CURL?
Oto wytyczne, które mogą ułatwić implementację CURL.
- Załaduj dokument do sprawdzenia plagiatu https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Wyświetl raport https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

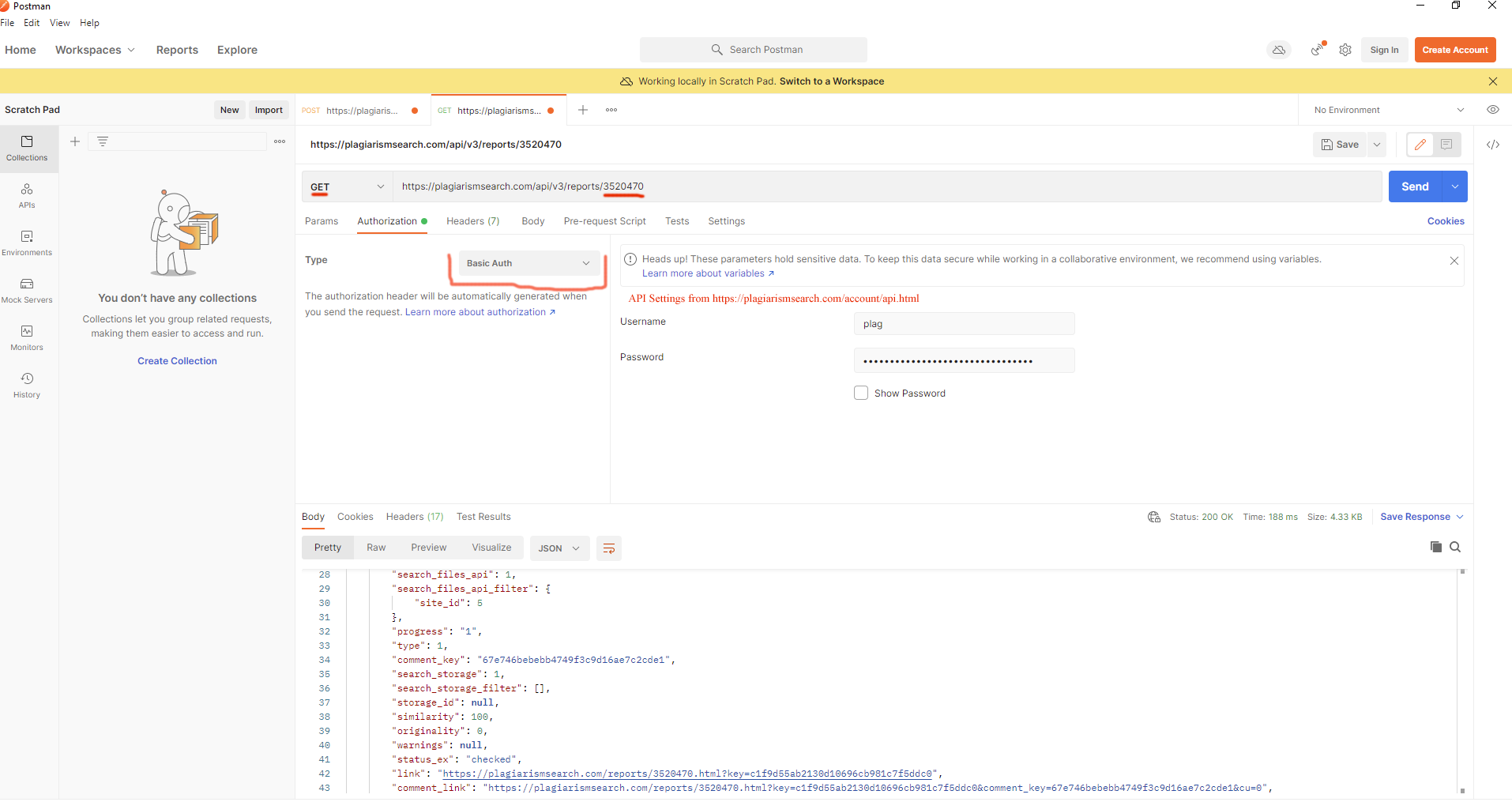
Dlaczego dokument ma status "Pending" w magazynie?
Dokument zazwyczaj pozostaje w statusie "Pending" przez krótki czas, od 0 do 6 minut po jego załadowaniu lub ponownym załadowaniu. Dokument jest natychmiast dodawany do indeksu wyszukiwania.
Możesz to również sprawdzić w kodzie programu: jeśli minęło 6 minut, dokument ma status Aktywny.
Można sprawdzić status dokumentu za pomocą następującej metody:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Zobacz pole `data.is_in_index`
Jak przesłać dokumenty do magazynu za pomocą API?
Możesz przesyłać dokumenty za pomocą API:
POST https://plagiarismsearch.com/api/v3/storage/create
z parametrami, które są podobne do https://plagiarismsearch.com/docs/v3/reports/create
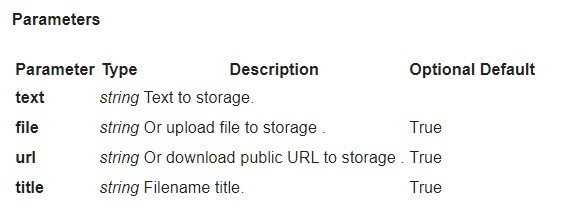
Alternatywnie, możesz przesyłać dokumenty w liście lub archiwum za pomocą formularza https://plagiarismsearch.com/storage/upload
Jakie są możliwości konta resellerów? Jak zintegrować je z moim systemem?
Funkcjonalności oferowane przez nasze konto resellerów to:
- Każdy nowy użytkownik musi być tworzony za pomocą API (będziesz potrzebować loginu i hasła, aby utworzyć konto użytkownika)
- Będziesz miał możliwość przydzielania określonej liczby słów dla każdego użytkownika za pośrednictwem konta reseller
Te opcje umożliwią każdemu klientowi korzystanie z jego konta niezależnie, a Ty będziesz mógł dodać słowa potrzebne dla każdego użytkownika
Dokumentacja techniczna niezbędna do integracji:
Aby móc tworzyć klientów, musisz mieć konto typu reseller.
Skontaktuj się z nami pod adresem services@plagiarismsearch.com , aby
uzyskać dostęp do pełnych możliwości konta resellera.
Utwórz klienta
Aby utworzyć nowego klienta, wyślij żądanie POST https://plagiarismsearch.com/api/v3/reseller-customers/create (adres e-mail klienta jest wymaganym polem)
Na przykład:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
twoja_klucz_użytkownika_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="Imię Użytkownika"' \
--form 'password="123456"'
Odpowiedź
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"Imię Użytkownika",
"status":"aktywne",
"password":"123456"
},
"version":"3.0.0"
}Lista klientów
Wyślij żądanie GET 'https://plagiarismsearch.com/api/v3/reseller-customers', aby otrzymać listę wszystkich utworzonych klientów.
Na przykład:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic twoja_klucz_użytkownika_combination=='
Pokaż salda
Wyślij żądanie GET https://plagiarismsearch.com/api/v3/reseller-customers/balance aby zobaczyć swoje saldo.
Uzyskaj saldo klienta
Wyślij żądanie GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} aby zobaczyć saldo konkretnego klienta.
Przykład odpowiedzi salda:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Słowa",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Zgłoszenia",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Zapłać za saldo klienta
Dodaj odpowiednią liczbę zgłoszeń lub słów do konta konkretnego klienta, wpisując identyfikator użytkownika i wpisując kwotę w polu `words` lub `submissions` (1 zgłoszenie = 1000 słów).
Na przykład:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic twoja_klucz_użytkownika_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Słowa"
},
"version":"3.0.0"
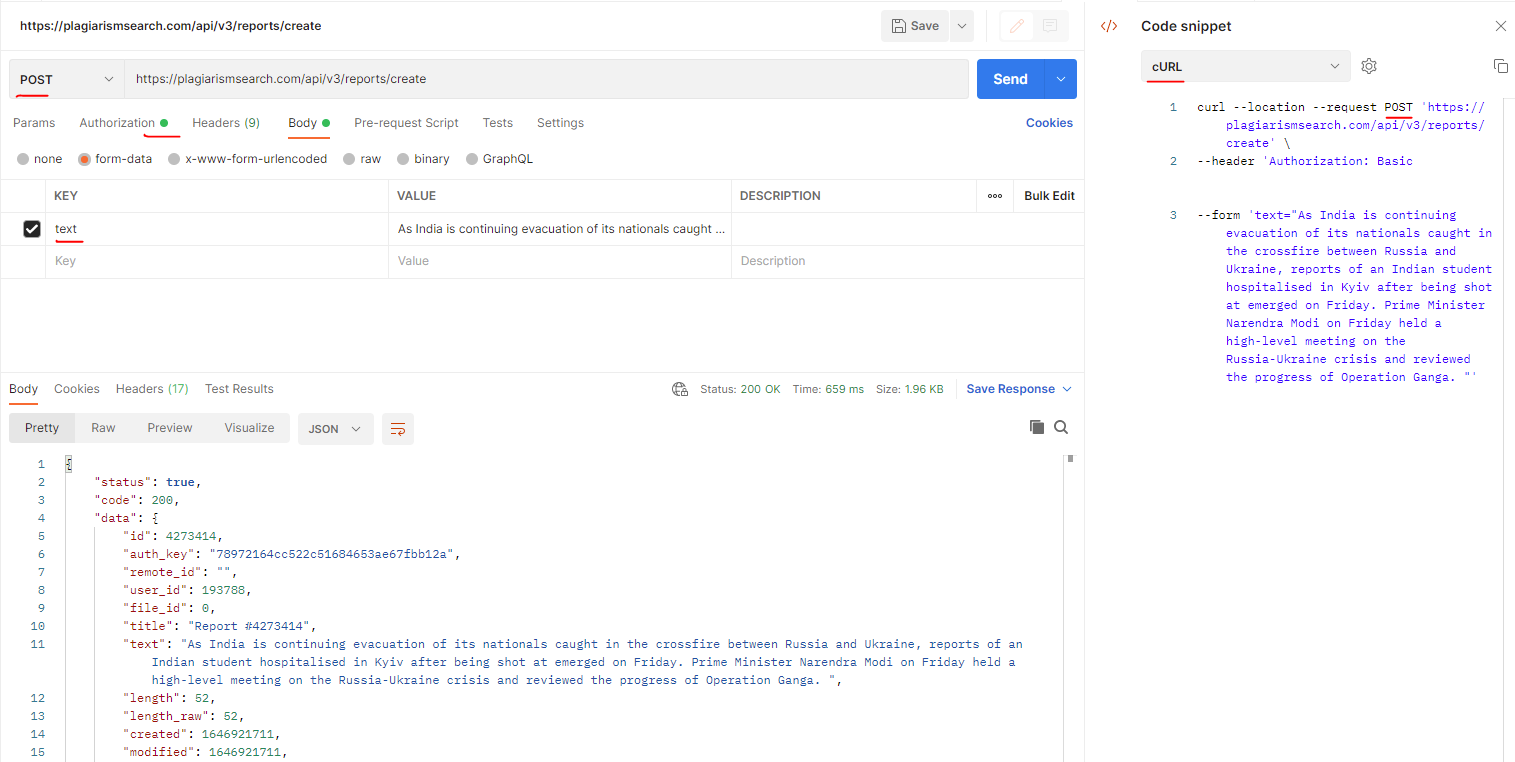
}Jak poprawić błąd: 400 Bad Request przy przesyłaniu tekstu do sprawdzenia plagiatu?
Przykład błędu, który możesz otrzymać przy przesyłaniu tekstu do sprawdzenia plagiatu może wyglądać tak:
Metoda żądania: PUT
Status Code: 400 Bad Request
Odpowiedź: Brak dostępnych instancji dla plagiarismsearch.com
API użyte: https://plagiarismsearch.com/api/v3/reports/create
Rozwiązanie:
Klient powinien używać metody POST (a nie PUT), jak na zrzucie ekranu
Wystąpił błąd uwierzytelniania podczas uruchamiania /report na GET za pomocą modułu request w Pythonie.
Musisz wysłać dane dotyczące uwierzytelniania przy każdym nowym żądaniu.
Używamy uwierzytelniania podstawowego, jak https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Uwierzytelnianie podstawowe Php przy użyciu CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);