API PlagiarismSearch: Preguntas y Respuestas

La API (Interfaz de Programación de Aplicaciones) es un conjunto de rutinas, protocolos y herramientas para la construcción de aplicaciones de software. Está diseñada para ayudar a las organizaciones a verificar grandes cantidades de texto a través de su sistema. Nuestra API ofrece a los clientes una oportunidad única de integrar nuestro software en sus propios sistemas, haciendo que el proceso de verificación de plagio sea automatizado. Como la integración de la API requiere conocimientos específicos y normalmente es realizada por especialistas técnicos, surgen muchas preguntas sobre sus características particulares para garantizar un funcionamiento eficiente. En este artículo, hemos reunido las preguntas y respuestas más populares sobre el rendimiento de nuestra API, así como soluciones para los problemas más frecuentes que enfrentan nuestros clientes durante el proceso de integración.
Además, la integración de la API ofrece a nuestros clientes la oportunidad de aprovechar el Almacenamiento Personal. Los clientes pueden cargar sus propios archivos en el sistema de Almacenamiento y guardar los textos verificados por plagio a través de nuestra API, creando así un Almacenamiento individual. Verificar textos para detectar plagio contra el Almacenamiento Personal permite a nuestros clientes detectar y prevenir el autoplagio. Lea más sobre las funcionalidades del Almacenamiento Personal en nuestra guía https://plagiarismsearch.com/plagiarism-database.
¿Qué funciones están disponibles a través de la API?
- Verificación de textos y documentos por plagio
- Acceso a los informes de plagio (historial de verificaciones de plagio)
- Capacidad de cargar la base de datos del cliente en el almacenamiento y visualizar los documentos en el almacenamiento
- Los revendedores tienen la oportunidad de crear varias cuentas de usuario y asignarles la cantidad adecuada de envíos/palabras. Estas opciones permitirán que cada referido use su cuenta de forma independiente.
¿Cómo puedo obtener acceso a la API?
Puede acceder a nuestra API de forma gratuita durante 30 días. También tendrá 100 envíos y Almacenamiento Personal para probar todos los beneficios de nuestro servicio. Por favor, regístrese utilizando este enlace para recibir acceso gratuito a la API: https://plagiarismsearch.com/es/account/signup?from=%2Faccount%2Fapi
Después de registrarse, vaya a Mi Perfil - Configuraciones de la API, y verá el Usuario y la Clave de la API proporcionados personalmente para su uso. Además, necesitará utilizar nuestra documentación de la API (haga clic en la sección de documentación de la API https://plagiarismsearch.com/docs/ en su Perfil para visualizarla). Proporcione acceso a la información anterior a su especialista técnico para comenzar a usar nuestra API.
¿Cómo funciona la API de verificación de plagio?
El esquema de operación de nuestra API es el siguiente:
- El usuario crea un informe (enviando un texto, subiendo un archivo o una URL pública) https://plagiarismsearch.com/docs/v3/reports/create
- Si su saldo está activo, su documento será añadido para verificación
- Si verifica entre 1000 y 3000 palabras de una vez, puede tardar de 30 a 60 segundos; más palabras tardan un poco más
- Después de verificar el documento, el usuario recibe una solicitud POST `callback_url` https://plagiarismsearch.com/docs/v3/reports/callback-request
- El ejemplo de uso de la API en PHP https://plagiarismsearch.com/files/sample-api.zip
¿La API garantiza la verificación automática del texto en tiempo real?
Sí, el proceso de verificación de plagio se realiza en tiempo real. Tarda de 1 a 5 minutos en verificar un texto; el tiempo de verificación de plagio depende del tamaño del texto.
¿Es posible preparar y descargar informes a través de la API?
Sí, puede descargar el informe en PDF o HTML justo después de que se complete la verificación de plagio. Todos los informes se almacenan en nuestra base de datos, por lo que puede acceder a ellos en cualquier momento y descargarlos https://plagiarismsearch.com/docs/v3/reports/view
¿Es posible crear mi propio modelo de informe?
No. Tenemos 2 modelos de informes disponibles. Solo puede insertar el logotipo de su empresa en nuestro modelo de informe.
¿La API permite la verificación de partes específicas del texto?
Sí, si se trata de incluir o excluir referencias o citas, colocando URLs específicas en la lista blanca.
¿Es posible visualizar el historial de verificaciones de texto a través de la API?
Sí, todos los informes se guardan en su base de datos.
¿Es una API REST o un plugin? ¿Es síncrona o asíncrona?
Ofrecemos una API RESTful. El acceso a nuestra documentación de la API está aquí: https://plagiarismsearch.com/docs/
Nuestra API es asíncrona. Cuando se completa la verificación de plagio, enviamos un web_hook al `callback_url` del usuario (https://plagiarismsearch.com/docs/v3/reports/callback-request).
¿Existen instrucciones sobre cómo implementar la API?
Un esquema más detallado de implementación de la API es el siguiente:
- Regístrese en nuestro sitio aquí https://plagiarismsearch.com/es/account/signup
- Asegúrese de que su saldo esté activo o inscríbase para una prueba gratuita de la API https://plagiarismsearch.com/es/account/signup?from=%2Faccount%2Fapi
- Vaya a Mi Perfil - Configuraciones de la API, y verá el Usuario de la API y la Clave proporcionados personalmente para su uso https://plagiarismsearch.com/pt/account/api
- Envíe un archivo o texto para
la verificación de plagio utilizando autenticación básica HTTP https://plagiarismsearch.com/docs/v3/reports/create.
Aquí hay un ejemplo en CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Recibirá una respuesta
con el ID del informe:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Nuestro motor de detección inicia el proceso de verificación de plagio.
- Una vez que la verificación de plagio se haya completado, el sistema envía un POST web_hook a la URL vinculada al documento enviado. Si no se ha indicado una URL, el sistema envía un POST web_hook a la URL vinculada a la cuenta del usuario.
- Existe una forma alternativa de definir
el estado de la verificación de plagio, aunque no es recomendada por nuestro equipo. Consiste en monitorear
el estado del informe https://plagiarismsearch.com/docs/v3/reports/status
dentro de ciertos intervalos de tiempo, y verificar si el estado del informe es
“Completado” (
status=2), “Error” (status=-10), o “Error del servidor” (status=-11) - Cuando el proceso de verificación de plagio haya finalizado, podrá obtener información detallada utilizando el ID del informe. Un ejemplo se puede encontrar aquí: https://plagiarismsearch.com/docs/v3/reports/view
También puede especificar el parámetro `show_relations` para obtener más datos.
Por ejemplo,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // por defecto
const RELATIONS_TREE = 1;
show_relations = -2 =>devuelve una lista de fuentes ordenadas por porcentaje de plagio. Consulte el campo de respuesta`data.sources`show_relations = -1 =>devuelve todos los datos del informe. Párrafos, frases y fuentes con texto resaltado. Consulte el campo de respuesta`data.paragraphs`show_relations = 1 =>devuelve todos los datos del informe. Párrafos, frases y fuentes con texto resaltado. Consulte el campo de respuesta`data.paragraphs`
¿Los scripts necesitan esperar el resultado del test de plagio o existe una función de callback que puede ser llamada más tarde para obtener el resultado del procesamiento del documento?
Hay una solicitud POST del URL del hook de callback que conectamos al usuario. También puede indicar su (personalizado) callback_url en las configuraciones al enviar su documento ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
El informe puede descargarse en varios formatos: (https://plagiarismsearch.com/docs/v3/reports/view) (Vea "Respuesta")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pública del informe en PDF
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // URL pública del informe en HTML
"files": [
{
// URL pública del informe en PDF versión 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // URL pública del informe en PDF versión 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // URL pública del informe en PDF versión 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // URL pública del informe en PDF versión 1 (actual)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}¿Cómo obtengo un informe en HTML?
Para recibir el enlace del informe en HTML, debe enviar una solicitud GET https://plagiarismsearch.com/api/v3/reports/{id} donde {id} es el ID del informe para el que desea recibir un informe. En la respuesta, encontrará el enlace del informe en el campo `data.link`. Además, en la respuesta, encontrará el 'data.auth_key' con el cual puede generar 3 variantes posibles de informes HTML.
Por ejemplo, hay 3 variantes posibles de informes HTML para data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Además, puede generar enlaces de informe en 4 idiomas diferentes (EN, ES, PL, RU).
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Puede combinar diferentes variantes de los informes HTML y los idiomas para recibir el tipo de informe necesario en el idioma elegido.
Un esquema similar puede ser usado para generar el enlace del informe en PDF (estas URLs pueden ser vistas en “Respuesta” -> `data.files`).
Por ejemplo:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...No puedo encontrar puntos finales/detalles sobre cómo generar tokens de acceso.
El token estará en su cuenta después de registrarse (https://plagiarismsearch.com/es/account/api).
Debe transmitirlo utilizando autenticación HTTP básica.
Php con CURL
// Autenticación HTTP básica
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
¿Puedo adjuntar archivos en DOCX, PDF y PPT para verificar? ¿Es esto posible?
Puede adjuntar archivos en varios formatos: (https://plagiarismsearch.com/docs/v3/reports/create) como cadena de archivo o cargar el archivo para su verificación.
Además, puede enviar archivos con el nombre `file`
Por ejemplo:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
¿Cómo puedo obtener la lista de URLs donde se encontró el texto?
Debe usar show_relations=1 o, si necesita solo las fuentes (enlaces => porcentaje de plagio), llamar a la ruta (método POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (aún no documentada) y usar el campo `data.sources`
¿Cómo puedo excluir mi URL de esta lista?
Puede llamar a la ruta (método POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (aún no documentada) después de la verificación del informe con parámetros POST
a) POST['url'] = 'https://wikipedia.org' o
b) POST['source'] = {source.id} (por ejemplo, data.sources[0].id (entero)) o
c) array de URLs excluidas
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array de IDs de fuentes excluidas
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Si llama a la ruta dos veces, los URLs se incluirán nuevamente, influyendo en el porcentaje general de plagio.
Para un uso más transparente, es mejor usar rutas con los mismos parámetros descritos arriba.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
También planeamos completar un conjunto de recursos que permitiría excluir URLs aquí: https://plagiarismsearch.com/api/v3/reports/create
¿Cómo puedo recalcular el porcentaje de plagio después de la exclusión?
La respuesta a la solicitud incluirá el porcentaje general (modificado) de plagio data.plagiat
¿Para qué sirven "filter_references" y "filter_quotes"?
filter_references=1 => excluye referencias. El texto de referencias no influye en el porcentaje total de plagio.
filter_quotes=1 => excluye citas en el texto. El texto de citas no influye en el porcentaje total de plagio. Los marcadores de citas son:
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
¿Hay una manera de implementar la API vía CURL?
Aquí están las directrices, que pueden facilitar su implementación con CURL.
- Cargar documento para verificación de plagio https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic su_combination_usuario_clave==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Visualizar informe https://plagiarismsearch.com/docs/v3/reports/view
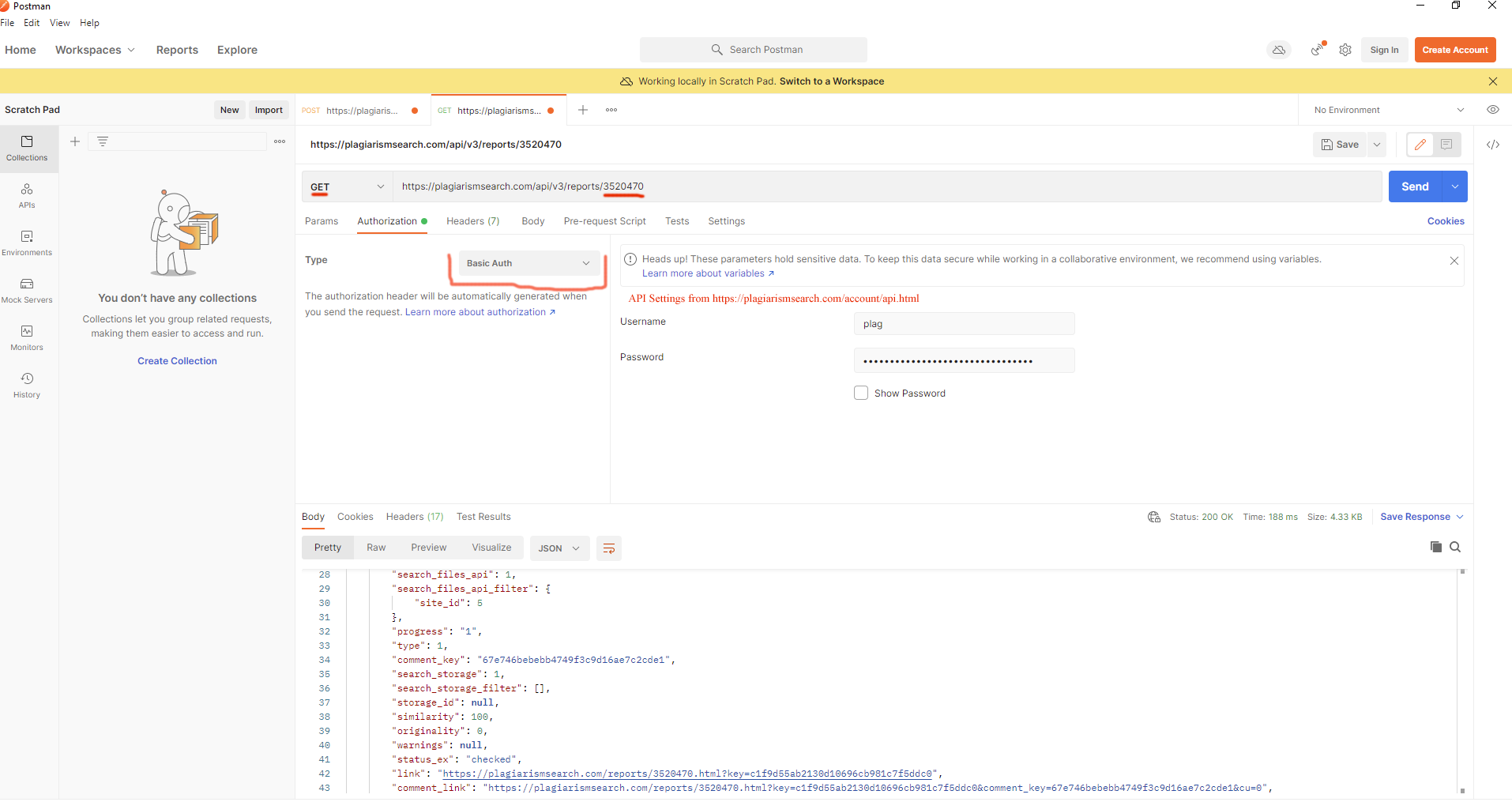
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic su_combinación_usuario_clave=='

¿Por qué el documento tiene el estado "Pendiente" en el Almacenamiento?
El documento generalmente se mantiene en estado Pendiente por un corto período, de 0 a 6 minutos después de ser cargado o reenviado. El documento se agrega inmediatamente al índice de búsqueda.
También puede verificar en el código del programa: si han pasado 6 minutos, el documento tendrá el estado Activo.
Es posible descubrir el estado del documento utilizando este método:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Mire el campo `data.is_in_index`
¿Cómo cargar documentos al almacenamiento mediante la API?
Puedes cargar tus documentos mediante la API:
POST https://plagiarismsearch.com/api/v3/storage/create
con parámetros similares a los de https://plagiarismsearch.com/docs/v3/reports/create
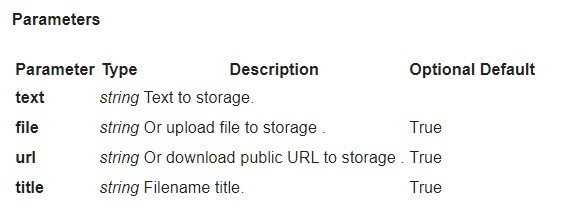
Alternativamente, puedes cargar documentos en una lista o archivo usando el formulario https://plagiarismsearch.com/storage/upload
¿Cuáles son las posibilidades de una cuenta de revendedor? ¿Cómo integrarla a mi propio sistema?
Las funcionalidades ofrecidas por nuestra cuenta de revendedor son:
- Cada nuevo usuario debe ser creado a través de la API (necesitarás un nombre de usuario y contraseña para crear cada cuenta de usuario)
- Tendrás la oportunidad de distribuir un número particular de palabras para cada usuario a través de la cuenta de revendedor.
Estas opciones permitirán que cada cliente use su cuenta de forma independiente, y podrás añadir las palabras necesarias para cada usuario
Documentación técnica necesaria para la integración:
Necesitas tener una cuenta de revendedor
para poder crear clientes. Contáctanos por correo electrónico a services@plagiarismsearch.com para
obtener acceso a las opciones completas de una cuenta de revendedor.
Crear cliente
Para crear un nuevo cliente, envía una solicitud POST https://plagiarismsearch.com/api/v3/reseller-customers/create (El correo electrónico del cliente es un campo obligatorio)
Por ejemplo:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="Nombre del Usuario"' \
--form 'password="123456"'
Respuesta
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"Nombre del Usuario",
"status":"activo",
"password":"123456"
},
"version":"3.0.0"
}Lista de clientes
Envía una solicitud GET 'https://plagiarismsearch.com/api/v3/reseller-customers' para recibir la lista de todos los clientes que han sido creados.
Por ejemplo:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Mostrar saldos
Envía una solicitud GET https://plagiarismsearch.com/api/v3/reseller-customers/balance para ver tu saldo.
Obtener tu saldo
Envía una solicitud GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} para ver el saldo de un cliente específico.
Ejemplo de respuesta de saldo:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Pagar para el saldo del cliente
Agregue el número necesario de envíos o palabras a la cuenta de un cliente específico, ingresando el ID del usuario y colocando el valor en el campo `words` o `submissions` (1 envío = 1000 palabras).
Por ejemplo:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
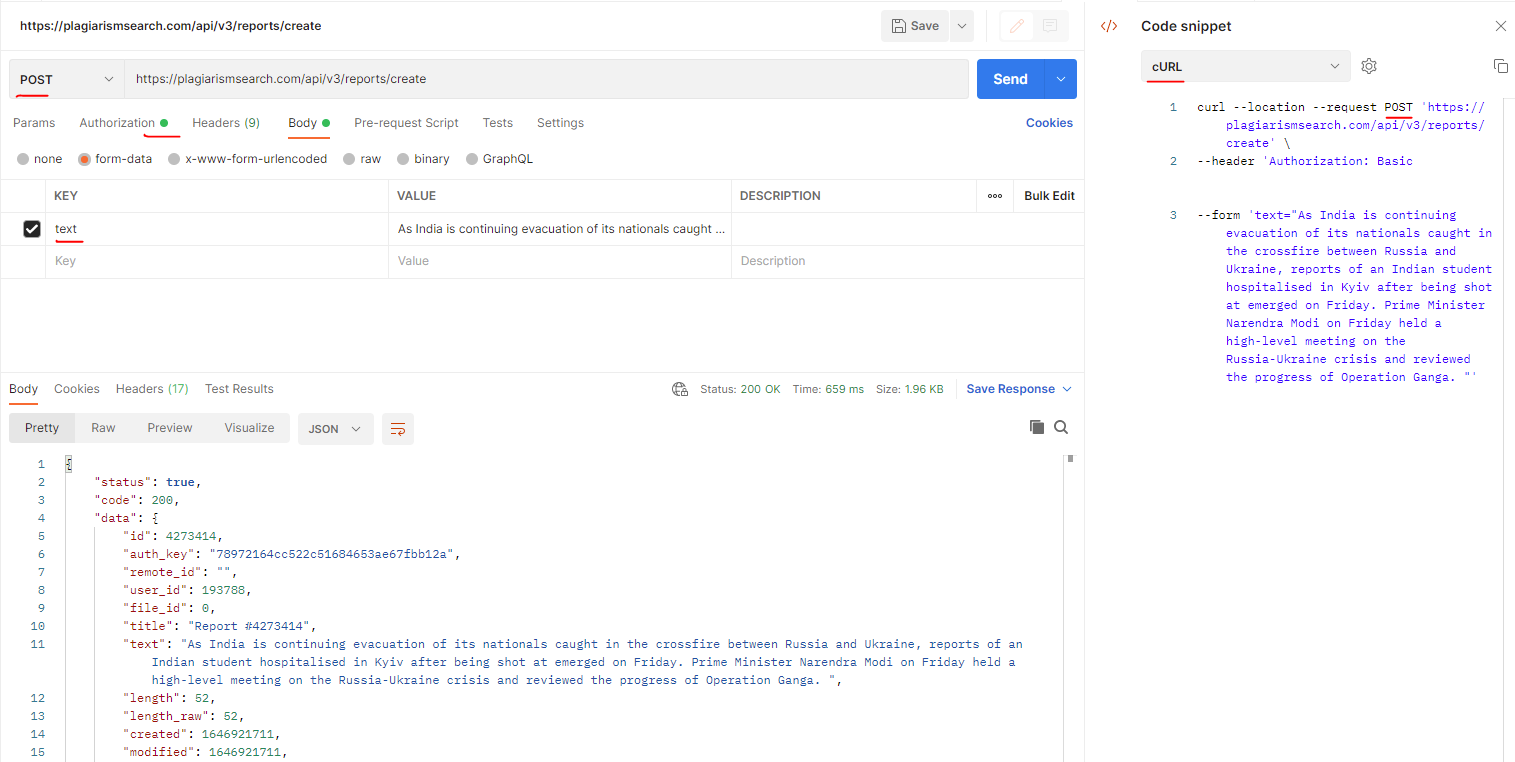
}¿Cómo corregir el error: 400 Bad Request al enviar texto para verificación de plagio?
El ejemplo de error que puede obtener al enviar texto para verificación de plagio puede ser similar a:
Método de solicitud: PUT
Código de estado: 400 Bad Request
Respuesta: Ninguna instancia disponible para plagiarismsearch.com
API de Plagio utilizada: https://plagiarismsearch.com/api/v3/reports/create
Solución:
El cliente debe usar el método POST (no PUT) como se muestra en la captura de pantalla
Hay un error de autenticación mientras estoy ejecutando el /report en GET usando el módulo request en Python.
Debe enviar los datos de autenticación en cada nueva solicitud.
Utilizamos autenticación básica, como https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// Autenticación básica HTTP Php usando CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);