PlagiarismSearch API: Питання та Відповіді

API (Інтерфейс програмування додатків) — це набір процедур, протоколів і інструментів для розробки програмних додатків. Він створений для допомоги організаціям у перевірці великих обсягів тексту через їхню систему. Наше API надає клієнтам унікальну можливість інтегрувати наше програмне забезпечення в їхні власні системи, щоб зробити процес перевірки на плагіат автоматизованим. Оскільки інтеграція API потребує специфічних знань і зазвичай виконується технічними спеціалістами, виникає багато запитань щодо його особливостей для забезпечення ефективної роботи. У статті ми зібрали найпопулярніші питання та відповіді щодо роботи нашого API і рішення найбільш поширених проблем, з якими стикаються наші клієнти під час процесу інтеграції.
Крім того, інтеграція API надає нашим клієнтам можливість скористатися персональним сховищем. Клієнти можуть завантажувати свої архіви в систему сховища і зберігати тексти, перевірені на плагіат через наше API, створюючи таким чином індивідуальне сховище. Перевірка текстів на плагіат з персональним сховищем дозволяє нашим клієнтам виявляти та запобігати самоплагіату. Дізнайтеся більше про функціональність персонального сховища в нашому посібнику https://plagiarismsearch.com/plagiarism-database.
Які функції доступні через API?
- Перевірка текстів та документів на плагіат
- Доступ до звітів про плагіат (історія перевірок на плагіат)
- Можливість завантажити базу даних клієнта в сховище та переглядати документи в сховищі
- Перепродувальники мають можливість створювати кілька облікових записів користувачів та призначати їм відповідну кількість подань/слова. Ці опції дають можливість кожному користувачу використовувати свій обліковий запис незалежно.
Як я можу отримати доступ до API?
Ви можете отримати доступ до нашого API безкоштовно на 30 днів. Ви також отримаєте 100 подань та персональне сховище для тестування всіх переваг нашого сервісу. Будь ласка, зареєструйтеся за цим посиланням, щоб отримати доступ до безкоштовного API: https://plagiarismsearch.com/ua/account/signup?from=%2Faccount%2Fapi
Після реєстрації перейдіть до Мого профілю - Налаштування API, і ви побачите користувача API та ключ, надані спеціально для вашого використання. Також вам слід використовувати нашу документацію API (натисніть на розділ документації API https://plagiarismsearch.com/docs/ у вашому профілі для перегляду). Надати доступ до цієї інформації вашому технічному спеціалісту для початку використання нашого API.
Як працює API перевірки на плагіат?
Схема роботи нашого API виглядає наступним чином:
- Користувач створює звіт (надаючи текст, завантажуючи файл або публічне URL) https://plagiarismsearch.com/docs/v3/reports/create
- Якщо ваш баланс активний — ваш документ додається для перевірки
- Якщо ви перевіряєте 1000-3000 слів одночасно, це може зайняти 30-60 секунд; більше слів займає трохи більше часу
- Після перевірки документа користувач отримує запит `callback_url` POST https://plagiarismsearch.com/docs/v3/reports/callback-request
- Приклад використання API на PHP https://plagiarismsearch.com/files/sample-api.zip
Чи забезпечує API автоматичну перевірку тексту в реальному часі?
Так, процес перевірки на плагіат здійснюється в реальному часі. Перевірка тексту займає від 1 до 5 хвилин, час перевірки залежить від розміру тексту.
Чи можливо підготувати та завантажити звіти через API?
Так, ви можете завантажити PDF або HTML звіт відразу після завершення перевірки на плагіат. Усі звіти зберігаються в нашій базі даних, тому ви можете отримати доступ до них у будь-який час і завантажити https://plagiarismsearch.com/docs/v3/reports/view
Чи можливо створити власний шаблон звіту?
Ні. Ми маємо 2 доступні шаблони звітів. Ви можете лише вставити логотип вашої компанії в наш шаблон звіту.
Чи дозволяє API перевіряти конкретні частини тексту?
Так, якщо ви маєте на увазі включення або виключення посилань чи цитат, а також додавання в білий список певних URL.
Чи можливо переглядати історію перевірок тексту через API?
Так, усі звіти зберігаються у вашій базі даних.
Чи це REST API чи плагін? Чи є воно синхронним чи асинхронним?
Ми надаємо RESTful API. Доступ до нашої документації API тут: https://plagiarismsearch.com/docs/
Наш API є асинхронним. Коли перевірка на плагіат завершена, ми відправляємо web_hook на callback_url користувача (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Чи є інструкція з реалізації API?
Більш детальна схема реалізації API виглядає так:
- Зареєструйтесь на нашому сайті тут https://plagiarismsearch.com/ua/account/signup
- Переконайтесь, що ваш баланс активний або зареєструйтесь для безкоштовної пробної версії API https://plagiarismsearch.com/ua/account/signup?from=%2Faccount%2Fapi
- Перейдіть до Мого профілю - Налаштування API, і ви побачите API користувача та ключ, надані особисто для вашого використання https://plagiarismsearch.com/account/api
- Відправте файл або текст для перевірки на плагіат за допомогою HTTP базової аутентифікації https://plagiarismsearch.com/docs/v3/reports/create.
Ось приклад у CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - Ви отримаєте відповідь
з ID звіту:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Наш двигун виявлення починає процес перевірки на плагіат.
- Після завершення перевірки на плагіат система надсилає POST web_hook на URL, який пов'язаний з надісланим документом. Якщо URL не був вказаний, система надсилає POST web_hook на URL, пов'язаний з обліковим записом користувача.
- Є альтернативний спосіб встановити
статус перевірки на плагіат, хоча це не рекомендується нашою командою. Це моніторинг
статусу звіту https://plagiarismsearch.com/docs/v3/reports/status
з певними інтервалами часу, і перевірка, чи статус звіту є
"Завершено" (
status=2), "Помилка" (status=-10), або "Помилка сервера" (status=-11) - Коли процес перевірки на плагіат завершено, ви можете отримати детальну інформацію за допомогою ID звіту. Один з прикладів можна знайти тут: https://plagiarismsearch.com/docs/v3/reports/view
Ви також можете вказати параметр `show_relations`, щоб отримати більше даних.
Наприклад,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // за замовчуванням
const RELATIONS_TREE = 1;
show_relations = -2 =>повертає список джерел, упорядкованих за відсотком плагіату. Дивіться поле відповіді`data.sources`show_relations = -1 =>повертає всі дані звіту. Параграфи, речення та джерела з виділеним текстом. Дивіться поле відповіді`data.paragraphs`show_relations = 1 =>повертає всі дані звіту. Параграфи, речення та джерела з виділеним текстом. Дивіться поле відповіді`data.paragraphs`
Чи потрібно скриптам чекати результат тесту на плагіат, чи є функція зворотного виклику, яку можна викликати пізніше для отримання результатів обробки документа?
Є хук зворотного виклику POST URL запиту, до якого ми підключаємо користувача. Ви також можете вказати свій (кастомний) callback_url у налаштуваннях при подачі документа ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
Звіт можна завантажити в кількох форматах: (https://plagiarismsearch.com/docs/v3/reports/view) (Дивіться "Response")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // публічне pdf посилання на звіт
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // публічне html посилання на звіт
"files": [
{
// публічне EN pdf посилання на звіт версія 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // публічне ES pdf посилання на звіт версія 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // публічне PL pdf посилання на звіт версія 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // публічне EN pdf посилання на звіт версія 1 (поточна)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}Як отримати HTML звіт?
Щоб отримати посилання на HTML звіт, вам потрібно надіслати GET запит https://plagiarismsearch.com/api/v3/reports/{id} де {id} — це ідентифікатор звіту, для якого ви хочете отримати звіт. В "Response" даних ви знайдете посилання на звіт у полі `data.link`. Також в "Response" ви знайдете 'data.auth_key', за допомогою якого ви можете згенерувати 3 можливі варіанти HTML звітів.
Наприклад, існує 3 можливі варіанти HTML звітів для data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Додатково ви можете генерувати посилання на звіти на 4 різних мовах (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
Ви можете поєднувати різні варіанти HTML звітів та мов для отримання необхідного типу звіту на вибраній мові.
Подібну схему можна використовувати для створення посилання на звіт у форматі PDF (ці URL-адреси можна переглянути в розділі "Response" -> `data.files`).
Наприклад:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...Я не можу знайти точки доступу/деталі про те, як генерувати токени доступу.
Токен буде у вашому обліковому записі після реєстрації (https://plagiarismsearch.com/ua/account/api)
Необхідно передавати його за допомогою базової HTTP автентифікації.
PHP з CURL
// Базова HTTP автентифікація
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
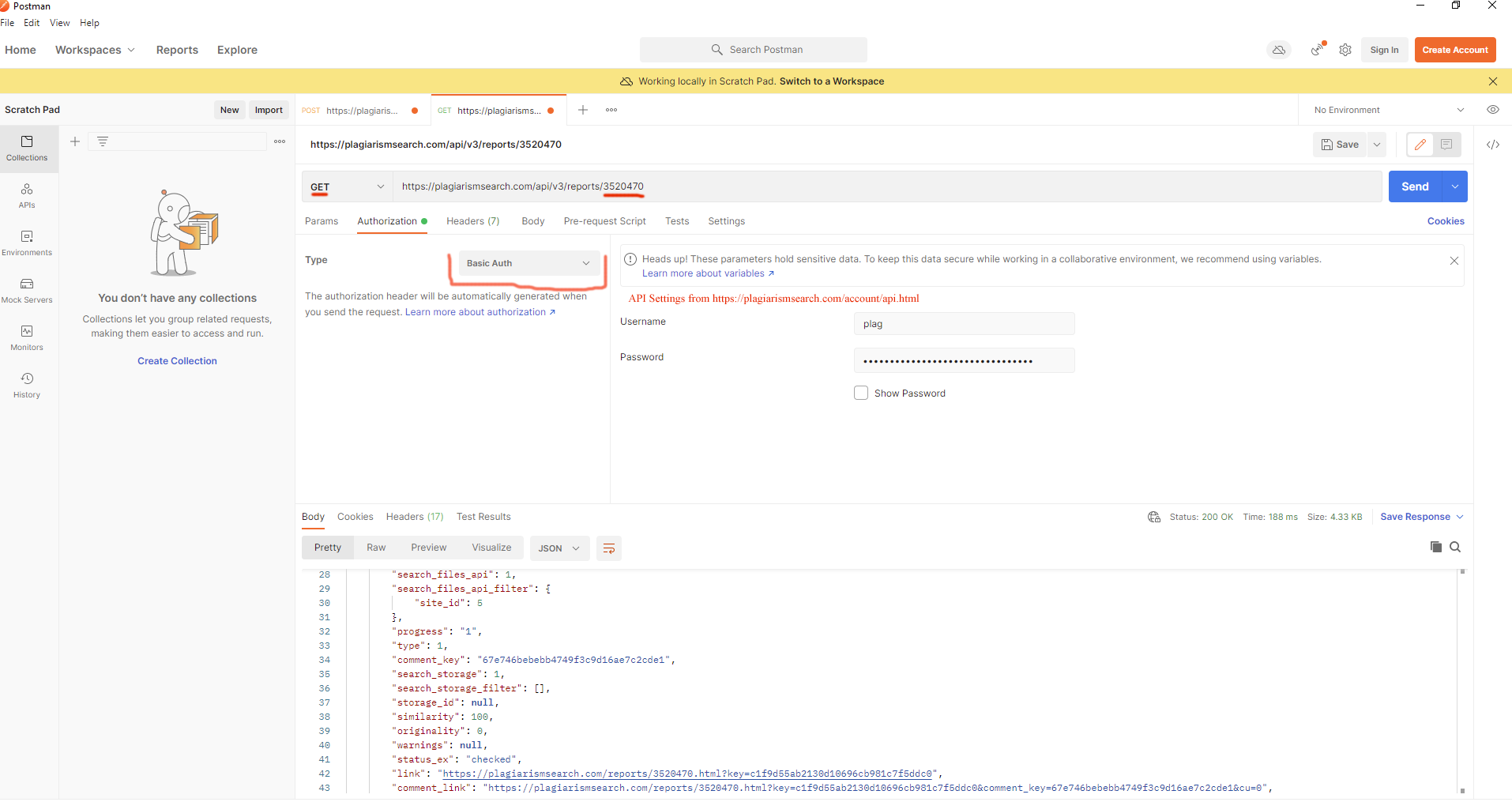
Я хотів би додати файли у форматах DOCX, PDF і PPT для перевірки. Чи це можливо?
Ви можете додавати файли в різних форматах: (https://plagiarismsearch.com/docs/v3/reports/create) рядок файлу або завантажити файл для перевірки.
Крім того, ви можете надіслати файли з іменем `file`
Наприклад:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
Як я можу отримати список URL-адрес, де знайдено текст?
Ви повинні використовувати show_relations=1, або, якщо вам потрібні лише джерела (посилання => відсоток плагіату), викликати маршрут (метод POST) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (на даний момент не задокументовано) і використовувати поле `data.sources`
Як я можу виключити своє посилання зі списку?
Ви можете викликати маршрут (метод POST) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (на даний момент не задокументовано) після перевірки звіту з параметрами POST
a) POST['url'] = 'https://wikipedia.org' або
b) POST['source'] = {source.id} (наприклад, data.sources[0].id (ціле число)) або
c) масив пропущених URL-адрес
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
масив пропущених ідентифікаторів джерел
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
Якщо ви викликаєте маршрут двічі, URL-адреси будуть знову включені, що вплине на загальний відсоток плагіату.
Для більш прозорого використання краще використовувати маршрути з тими ж параметрами, які були описані вище.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
Ми також плануємо завершити набір функцій, який дозволить виключати URL-адреси тут: https://plagiarismsearch.com/api/v3/reports/create
Як я можу перерахувати відсоток плагіату після виключення?
Відповідь на запит включатиме загальний (змінений) відсоток плагіату data.plagiat
Що таке "filter_references" і "filter_quotes"?
filter_references=1 => виключити посилання. Текст посилань не має ваги на загальний відсоток плагіату
filter_quotes=1 => виключити цитати в тексті. Текст цитат не має ваги на загальний відсоток плагіату. Маркери цитування це
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
Чи є спосіб реалізувати API через CURL?
Ось кілька рекомендацій, які можуть полегшити вашу реалізацію CURL.
- Завантажте документ для перевірки на плагіат https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- Переглянути звіт https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Чому документ має статус “Очікує” в сховищі?
Документ зазвичай залишається в статусі "Очікує" не довго, від 0 до 6 хвилин після завантаження або повторного завантаження. Документ миттєво додається до індексу пошуку.
Ви також можете перевірити це в коді програми: якщо пройшло 6 хвилин, документ має статус "Активний".
Статус документа можна дізнатися за допомогою наступного методу:
GET https://plagiarismsearch.com/api/v3/storage/{id}
Дивіться поле `data.is_in_index`
Як завантажити документи в сховище через API?
Ви можете завантажити свої документи через API:
POST https://plagiarismsearch.com/api/v3/storage/create
з параметрами, схожими на https://plagiarismsearch.com/docs/v3/reports/create
Альтернативно, ви можете завантажити документи в списку або архіві за допомогою форми https://plagiarismsearch.com/storage/upload
Які можливості має акаунт реселлера? Як інтегрувати його в свою систему?
Функціональні можливості нашого акаунта реселлера:
- Кожен новий користувач має бути створений через API (вам буде потрібен логін і пароль для створення кожного облікового запису)
- Ви матимете можливість надавати певну кількість слів кожному користувачеві через акаунт реселлера.
Ці опції дозволять кожному клієнту використовувати свій акаунт незалежно, і ви зможете додавати необхідну кількість слів для кожного користувача.
Технічна документація для інтеграції:
Вам потрібно мати акаунт типу реселлер,
щоб мати можливість створювати клієнтів. Зв'яжіться з нами за адресою services@plagiarismsearch.com
для отримання доступу до всіх можливостей акаунта реселлера.
Створити клієнта
Щоб створити нового клієнта, надішліть POST запит https://plagiarismsearch.com/api/v3/reseller-customers/create (Електронна пошта клієнта є обов'язковим полем)
Наприклад:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Відповідь
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}Список клієнтів
Надішліть GET запит 'https://plagiarismsearch.com/api/v3/reseller-customers', щоб отримати список всіх клієнтів, яких було створено.
Наприклад:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Показати баланси
Надішліть GET запит https://plagiarismsearch.com/api/v3/reseller-customers/balance щоб переглянути ваш баланс.
Отримати баланс клієнта
Надішліть GET запит https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} щоб переглянути баланс конкретного клієнта.
Приклад відповіді по балансу:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Оплатити баланс клієнта
Додайте необхідну кількість подань або слів на акаунт конкретного клієнта, ввівши ID користувача та зазначивши кількість у полі `words` або `submissions` (1 подання = 1000 слів).
Наприклад:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
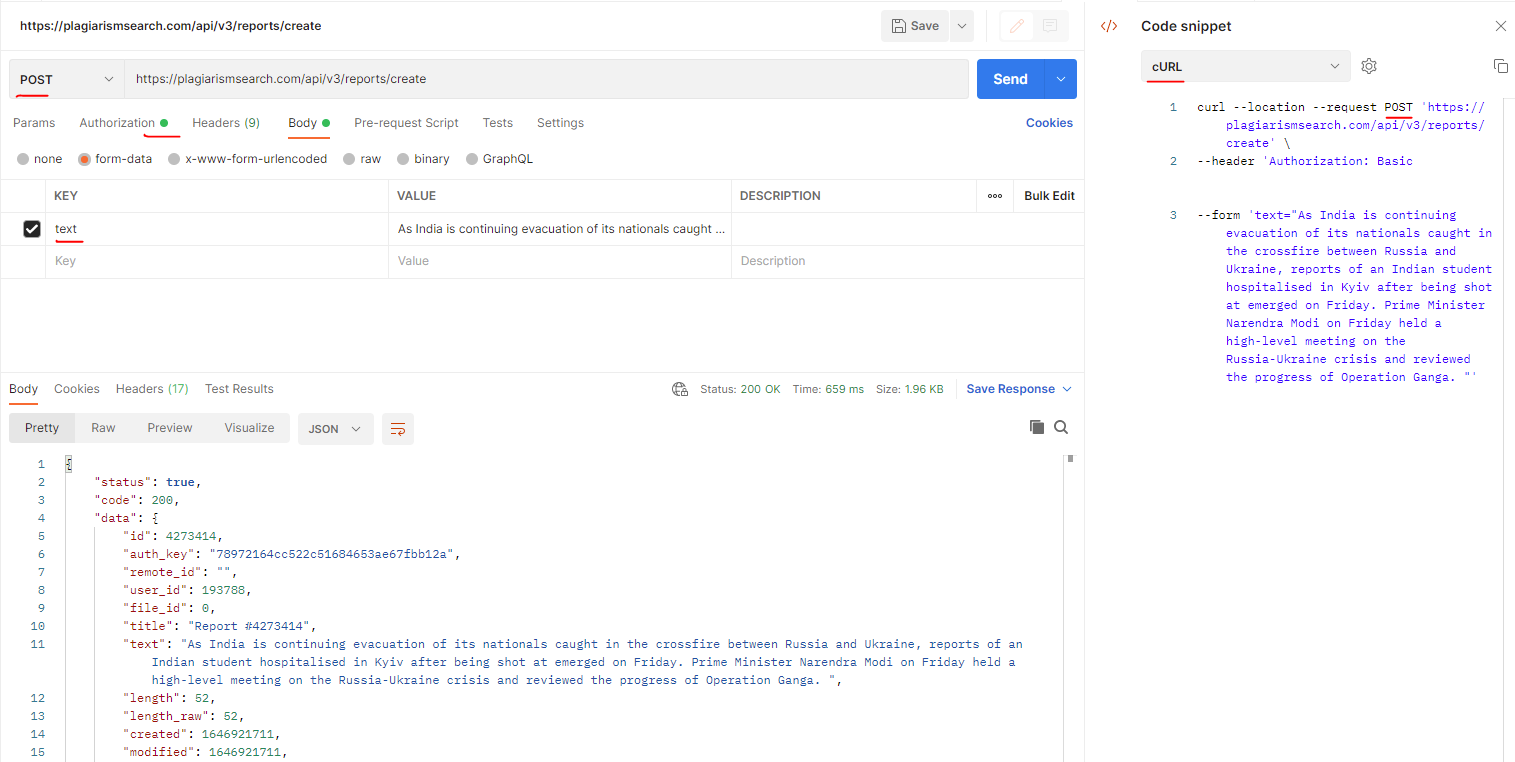
}Як виправити помилку: 400 Bad Request при подачі тексту на плагіат?
Приклад помилки, яку ви можете отримати при подачі тексту на плагіат, може виглядати так:
Метод запиту: PUT
Код статусу: 400 Bad Request
Відповідь: No instances available for plagiarismsearch.com
API плагіату використано: https://plagiarismsearch.com/api/v3/reports/create
Рішення:
Клієнт має використовувати метод POST (а не PUT) як на скріншоті
Є помилка аутентифікації, коли я виконую /report на GET, використовуючи модуль request в Python.
Необхідно надсилати дані для аутентифікації при кожному новому запиті.
Ми використовуємо Basic Authentication, як https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// HTTP basic authentication Php using CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);