PlagiarismSearch API: Questions and Answers

API (Application programming interface) is a set of routines, protocols, and tools for building software applications. It is created to help organizations to check large amounts of text through their system. Our API gives the customers a unique opportunity to integrate our software into their own systems to make plagiarism check an automated process. Since the API integration requires specific knowledge and is usually completed by technical specialists, many questions arise about its particular features to ensure efficient operation. In the article we gathered the most popular questions-answers about our API performance, and solutions to the most frequent problems that our customers face during the process of integration.
Additionally, the API integration gives our clients an opportunity to take advantage of the personal Storage. Customers may upload their own archives into the Storage system and save the texts checked for plagiarism through our API, thus creating an individual Storage. Checking texts for plagiarism against the personal Storage allows our customers to detect and prevent self-plagiarism. Read more about the functionalities of the personal storage in our guide https://plagiarismsearch.com/plagiarism-database.
What features are available through the API?
- Checking texts and document for plagiarism
- Access to plagiarism reports (history of plagiarism checks)
- Ability to upload client’s database into the storage and view the documents in the storage
- Resellers have the opportunity to create multiple user accounts and assign them with appropriate number of submissions/words. These options will give the possibility for each referral to use his/her account independently.
How can I get access to the API?
You can have access to our API for free for 30 days. You will also have 100 submissions and personal Storage to test all the benefits of our service. Please register using this link to receive access to free API: https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
After you register, go to My Profile - API Settings, and you will see API User and Key provided personally for your use. Also, you will need to use our API documentation (click on API documentation section https://plagiarismsearch.com/docs/ in Your Profile to view it). Provide access to the above information for your technical specialist to start using our API.
How Does the plagiarism check API work?
The scheme of our API operation is as follows:
- The user creates a report (by submitting a text, uploading a file, or a public URL) https://plagiarismsearch.com/docs/v3/reports/create
- If your balance is active – your document is added for checking
- If you check 1000-3000 words at once, it can take 30-60 seconds; more words take slightly longer
- After checking the document, the user gets a`callback_url` POST request https://plagiarismsearch.com/docs/v3/reports/callback-request
- The sample of the API usage at PHP https://plagiarismsearch.com/files/sample-api.zip
Does the API ensure automatic text verification in real time?
Yes, the plagiarism check process is performed in real time. It takes 1-5 minutes to check a text, the time of plagiarism check depends on the size of the text.
Is it possible to prepare and download reports through the API?
Yes, you can download PDF or HTML report right after plagiarism check is completed. All reports are stored in our database, so you can access them at any time and download https://plagiarismsearch.com/docs/v3/reports/view
Is it possible to create my own report template?
No. We have 2 available report templates. You can only insert your company's logo into our report template.
Does the API enable specific parts of the text verification?
Yes, if you are talking about including or excluding references or citations, whitelisting particular URLs.
Is it possible to view the history of text checking through the API?
Yes, all reports are saved in your database.
Is it REST API or plugin? Is it synchronous or asynchronous?
We provide RESTful API. The access to our API documentation is here: https://plagiarismsearch.com/docs/
Our API is asynchronous. When the plagiarism check is finished, we send a web_hook to user callback_url (https://plagiarismsearch.com/docs/v3/reports/callback-request).
Is there any instruction on how to implement the API?
A more elaborate scheme of API implementation is as follows:
- Register with our website here https://plagiarismsearch.com/account/signup
- Make sure your balance is active or sign up for a free API trial https://plagiarismsearch.com/account/signup?from=%2Faccount%2Fapi
- Go to My Profile - API Settings, and you will see API User and Key provided personally for your use https://plagiarismsearch.com/account/api
- Send a file or text for
plagiarism check using HTTP basic authentication https://plagiarismsearch.com/docs/v3/reports/create.
Here is an example in CURL:
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey); - You will receive a response
with report ID:
"data": { "id": 100500, "auth_key": "65jdgjhh7h452hjkh45k7535", ... } - Our detection engine starts plagiarism check process.
- After the plagiarism check is completed, the system sends POST web_hook to the URL that is linked to the submitted document. In case the URL was not indicated, the system sends POST web_hook to the URL that is linked to the user’s account.
- There an alternative way to set
the status of plagiarism check, though, not recommended by our team. It is to monitor
the report status https://plagiarismsearch.com/docs/v3/reports/status
within certain time intervals, and check whether the report status is
“Finished” (
status=2), “Error” (status=-10), or “Server error” (status=-11) - When the process of plagiarism check is completed, you may get a detailed information using the report ID. One of the examples can be found here: https://plagiarismsearch.com/docs/v3/reports/view
You can additionally specify the parameter `show_relations` to get more data.
For instance,
const RELATIONS_SOURCES = -2;
const RELATIONS_RAW = -1;
const RELATIONS_NONE = 0; // default
const RELATIONS_TREE = 1;
show_relations = -2 =>return list of sources ordered by plagiarism percent. See`data.sources`response fieldshow_relations = -1 =>return all report data. Paragraphs, sentences and sources with highlight text. See`data.paragraphs`response fieldshow_relations = 1 =>return all report data. Paragraphs, sentences and sources with highlight text. See`data.paragraphs`response field
Do scripts need to wait for the result of the plagiarism test or is there a call back function that can be called at a later time to get the document processing result?
There is a callback hook POST URL request that we connect to the user. You can also indicate your (custom) callback_url in the settings when you submit your document ( https://plagiarismsearch.com/docs/v3/reports/create, https://plagiarismsearch.com/docs/v3/reports/callback-request)
The report can be downloaded in several formats: (https://plagiarismsearch.com/docs/v3/reports/view) (See "Response")
{
"status": true,
"code": 200,
"data": {
"file": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6", // public pdf report URL
"link": "https://plagiarismsearch.com/reports/100500?key=54fba6bc7d765cab653f2185a83284a6", // public html report URL
"files": [
{
// public EN pdf report URL version 3
"url": "https://plagiarismsearch.com/r/download100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 3
},
{ // public ES pdf report URL version 3
"url": "https://plagiarismsearch.com/es/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "es",
"version": 3
},
{ // public PL pdf report URL version 3
"url": "https://plagiarismsearch.com/pl/r/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "pl",
"version": 3
},
{ // public EN pdf report URL version 1 (current)
"url": "https://plagiarismsearch.com/reports/download/100500?key=54fba6bc7d765cab653f2185a83284a6",
"type": "application/pdf",
"language": "en",
"version": 1
}
]
}
}How do I get a HTML report?
To receive HTML report link you need to send GET request https://plagiarismsearch.com/api/v3/reports/{id} where {id} is the report ID you want to receive a report for. In “Response” data you will find the report link in `data.link` field. Also, in “Response” you will find ‘data.auth_key’ using which you may generate 3 possible variants of HTML reports.
For example, there are 3 possible variants of HTML reports for data.auth_key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/r/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/reports/lite/100500?key=65jdgjhh7h452hjkh45k7535
Additionally, you may generate report links in 4 different languages (EN, ES, PL, RU)
- https://plagiarismsearch.com/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/es/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/pl/reports/100500?key=65jdgjhh7h452hjkh45k7535
- https://plagiarismsearch.com/ru/reports/100500?key=65jdgjhh7h452hjkh45k7535
You are free to combine different variants of HTML reports and languages to receive a necessary type report on a chosen language.
Similar scheme can be used to generate PDF report link (these URLS can be viewed in “Response” -> `data.files`).
For example:
...
"files":[
{
"url":"https://plagiarismsearch.com/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"en",
"version":3
},
{
"url":"https://plagiarismsearch.com/es/r/download/100500?key=65jdgjhh7h452hjkh45k7535",
"type":"application/pdf",
"language":"es",
"version":3
}
]
...I am not able to find endpoints/details on how to generate access tokens.
The token will be in your account after you'll register (https://plagiarismsearch.com/account/api)
It is necessary to transmit it using Authentication HTTP basic.
Php with CURL
// HTTP basic authentication
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);
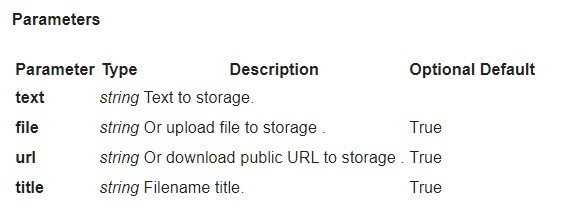
I would like to attach the files in DOCX, PDF and PPT to check. Is it possible?
You can attach files in multiple formats: (https://plagiarismsearch.com/docs/v3/reports/create) file string Or upload file for check.
Besides, you can send files with name `file`
For example:
curl -F 'file=@/home/petehouston/hello.txt' https://plagiarismsearch.com/api/v3/reports/create
How can I get the list of URLs where text was found?
You must use show_relations=1 or if you need only sources (links => percent of plagiarism) or call route (POST method) https://plagiarismsearch.com/api/v3/reports/sources/{reportId} (not documented now) and use `data.sources` field
How can I exclude my URL from this list?
You can call route (POST method) https://plagiarismsearch.com/api/v3/reports/skip/{reportId} (not documented now) after report check with post parameters
a) POST['url'] = 'https://wikipedia.org' or
b) POST['source'] = {source.id} (for example data.sources[0].id (integer)) or
c) array of skipped urls
POST['urls'][] = 'https://wikipedia.org'
POST['urls'][] = 'https://plagiarismsearch.com'
array of skipped source ids
POST['sources'][] = {source.id}
POST['sources'][] = {source.id2}
If you call route twice - URLs will be included again, influencing the general percentage of plagiarism
For a more transparent usage, it’s better to use routes with the same parameters as were described above.
https://plagiarismsearch.com/api/v3/reports/exclude/{reportId}
https://plagiarismsearch.com/api/v3/reports/include/{reportId}
We also plan to complete a feature set that would allow excluding URL here: https://plagiarismsearch.com/api/v3/reports/create
How can I recalculate plagiarism percentage after exclusion?
The response to the request will include the general (altered) percentage of plagiarism data.plagiat
What are "filter_references" & "filter_quotes" good for?
filter_references=1 => exclude references. References text has no weight on total plagiarism percent
filter_quotes=1 => exclude in-text citation. Citation text has no weight on total plagiarism percent. Citation markers are
array('«', '»'),
array('"', '"'),
array('“', '”'),
array('《', '》'),
array('〈', '〉'),
array('{*', '*}'),
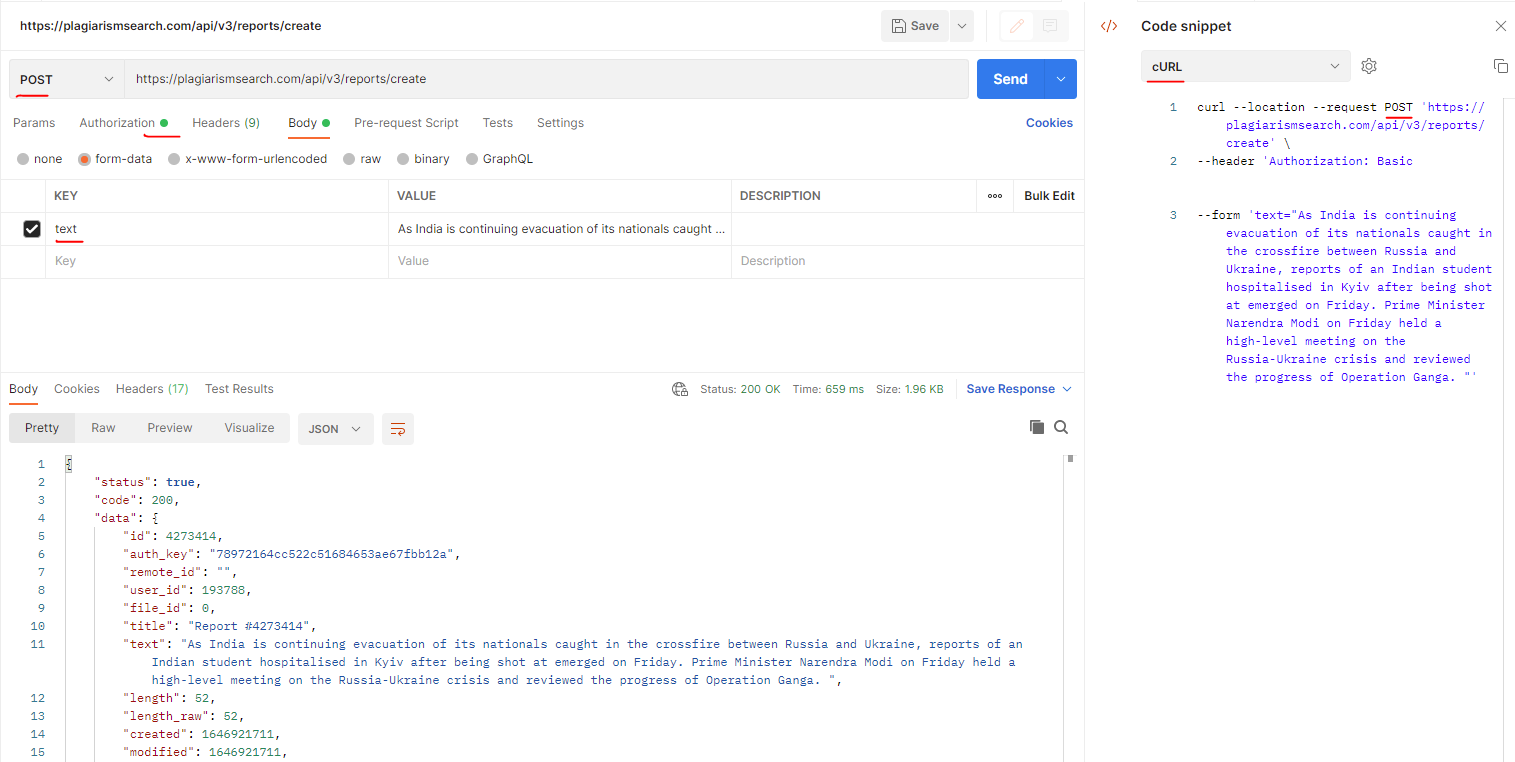
Is there a way to implement the API via CURL?
Here are the guidelines, which could ease your CURL implementation.
- Upload document for plagiarism check https://plagiarismsearch.com/docs/v3/reports/create
curl --location --request POST 'https://plagiarismsearch.com/api/v3/reports/create' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'search_web="1"' \
--form 'search_storage="1"' \
--form 'file=@"test_file_plagiarism.txt"'
- View report https://plagiarismsearch.com/docs/v3/reports/view
curl --location --request GET 'https://plagiarismsearch.com/api/v3/reports/3520470' \
--header 'Authorization: Basic your_user_key_combination=='

Why does the document have “Pending” status in Storage?
The document usually stays in Pending status not for a long time, from 0 to 6 minutes after it has been uploaded or reuploaded. The document is instantly added to the Search index.
You can also check it in the program's code: if 6 minutes passed, the document has Active status.
It is possible to find out the document status using such a method:
GET https://plagiarismsearch.com/api/v3/storage/{id}
See `data.is_in_index` field
How to upload documents to the storage via API?
You can upload your documents via API:
POST https://plagiarismsearch.com/api/v3/storage/create
with parameters, which are similar to https://plagiarismsearch.com/docs/v3/reports/create
Alternatively, you can upload documents in a list or an archive using the form https://plagiarismsearch.com/storage/upload
What are the possibilities of a reseller account? How do I integrate it in my own system?
The functionalities offered by our reseller account are:
- Each new user must be created through the API (you will need login and password to create each user account)
- You will have the opportunity to give out a particular number of words for each user through the reseller account.
These options will give the possibility for each client to use his/her account independently, and you will be able to add words necessary for every user
Technical documentation necessary for integration:
You need to have a reseller type of account
to be able to create customers. Contact us at services@plagiarismsearch.com to
receive access to full possibilities of a reseller account.
Create customer
To create a new customer, send POST request https://plagiarismsearch.com/api/v3/reseller-customers/create (Customer email is a required field)
For example:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/create' \
--header 'Authorization: Basic
your_user_key_combination===' \
--form 'email="testusermail@gmail.com"' \
--form 'name="User Name"' \
--form 'password="123456"'
Response
{
"status":true,
"code":200,
"data":{
"id":26784,
"email":"testusermail@gmail.com",
"name":"User Name",
"status":"active",
"password":"123456"
},
"version":"3.0.0"
}List of customers
Send a request GET 'https://plagiarismsearch.com/api/v3/reseller-customers' to receive the list of all customers that were created.
For example:
curl --location --request GET
'https://plagiarismsearch.com/api/v3/reseller-customers' \ --header
'Authorization: Basic your_user_key_combination=='
Show balances
Send a request GET https://plagiarismsearch.com/api/v3/reseller-customers/balance to view your balance.
Get your balance
Send a request GET https://plagiarismsearch.com/api/v3/reseller-customers/balance/{userId} to view the balance of a particular customer.
The example of balance response:
{
"status":true,
"code":200,
"data":{
"is_solvable":true,
"700":{
"type":"Words",
"amount":6001,
"expired":1878542044,
"is_valid":true,
"is_solvable":true
},
"300":{
"type":"Submissions",
"amount":4,
"expired":1720878480,
"is_valid":true,
"is_solvable":true
}
},
"version":"3.0.0"
}
Pay to customer’s balance
Add the necessary number of submissions or words to a particular customer’s account by entering user ID and entering the amount into `words` or `submissions` field (1 submissions = 1000 words).
For example:
curl --location --request POST
'https://plagiarismsearch.com/api/v3/reseller-customers/pay/26784' \
--header 'Authorization: Basic your_user_key_combination==' \
--form 'words="1000"'
{
"status":true,
"code":200,
"data":{
"payment_id":1171,
"amount":100,
"type":"Words"
},
"version":"3.0.0"
}How to correct Error: 400 Bad Request when submitting text for plagiarism?
The example error you may get when submitting text for plagiarism may look like:
Request Method: PUT
Status Code: 400 Bad Request
Response: No instances available for plagiarismsearch.com
Plagiarism API used: https://plagiarismsearch.com/api/v3/reports/create
Solution:
The customer should use POST Http method (not PUT) like on the screenshot
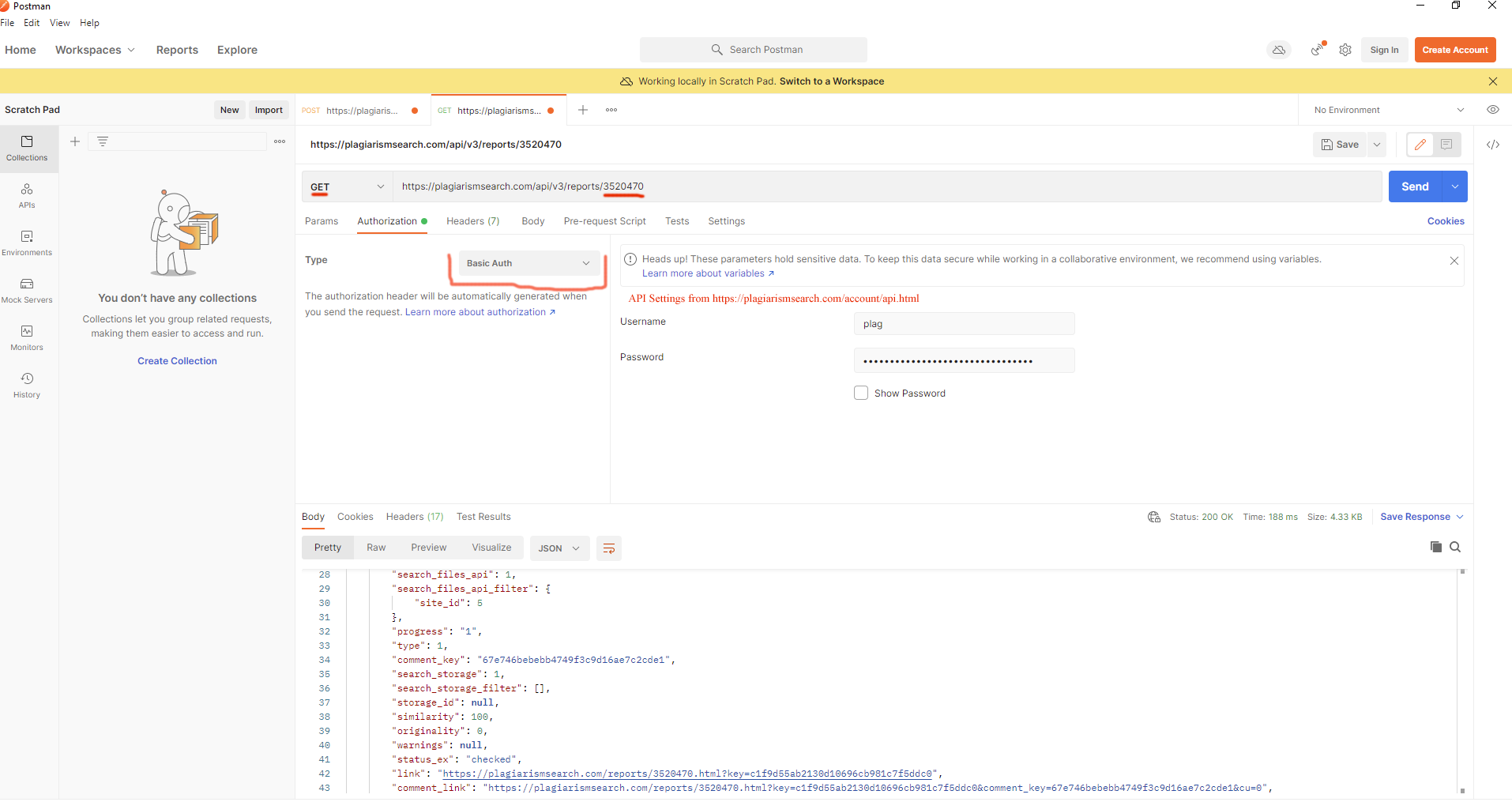
There is an authentication error while I am running the /report on GET using request module on Python.
You have to send the data regarding the authentication upon each new request.
We use Basic Authentication, such as< https://docs.python-requests.org/en/master/user/authentication/
from requests.auth import HTTPBasicAuth
>>> requests.get(' https://plagiarismsearch.com/api/v3/reports/{id}', auth=HTTPBasicAuth('apiUser', 'apiKey'))
// HTTP basic authentication Php using CURL
curl_setopt($curl, CURLOPT_USERPWD, $apiUser . ':' . $apiKey);